Dwayne Phillips works as a computer and electronics engineer with the United States Department of Defense. He has a Ph.D. in electrical and computer engineering at Louisiana State University. His interests include computer vision, artificial intelligence, software engineering, and programming languages.
Neural networks are one of the most capable and least understood technologies today. The theory of neural networks is a bit esoteric; the implications sound like science fiction but the implementation is beginner's C.
There are many problems that traditional computer programs have difficulty solving, but people routinely answer. Examples include predicting the weather or the stock market, interpreting images, and reading handwritten characters.
Since the brain performs these tasks easily, researchers attempt to build computing systems using the same architecture. The result, shown in Figure 1, is a neural network. A neural network is a computing system containing many small, simple processors connected together and operating in parallel. The structure of the neural network resembles the human brain, so neural networks can perform many human-like tasks but are neither magical nor difficult to implement.
How a Neural Network Learns
An important characteristic of a neural network is that it can "learn." Once you have a neural network program (such as those given later) you "train" it. You do not write a new program for every new problem. You use the same neural network program and train it to solve new problems.The basic building block of all neural networks is the adaptive linear combiner shown in Figure 2 and described by Equation 1. The adaptive linear combiner combines inputs (the x's) in a linear operation and adapts its weights (the w's). Put another way, it "learns." The adaptive linear combiner is not a neural network — it is only a building block.
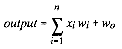
The adaptive linear combiner multiplies each input by each weight and adds up the results to reach the output. The software implementation uses a single for loop, as shown in Listing 1.
If the output is wrong, you change the weights until it is correct. The neural network "learns" through this changing of weights, or "training." The summation in the lower right of Figure 2 shows a path where errors can come back and change the weights to produce a correct answer.
I used the adaptive linear combiner to make a simple neural network — the adaptive linear element or Adaline (Widrow and Lehr 1990) shown in Figure 3. The Adaline is a linear classifier. It can separate data with a single, straight line. Figure 4 gives an example of this type of data. Suppose you measure the height and weight of two groups of professional athletes, such as linemen in football and jockeys in horse racing, then plot them. As expected, the linemen plot out in one area of the graph (the -1 group) and the jockeys in another (the +1 group). You can draw a single straight line separating the two groups.
You can feed these data points into an Adaline and it will learn how to separate them. Then you can give the Adaline new data points and it will tell us whether the points describe a lineman or a jockey. The inputs to the Adaline (the x's) are the sets of points (height and weight) and the output from the Adaline is +1 (jockey) or --1 (lineman). Each input (height and weight) is an input vector. The input vector is a C array that in this case has three elements: one for height, one for weight, and one extra (all input vectors have this extra element).
The Adaline contains two new items. These are the threshold device and the LMS algorithm, or learning law. The threshold device takes the sum of the products of inputs and weights and hard limits this sum using the signum function. If the sum is less than 1, the output is -1, else the output is +1. Listing 2 shows a subroutine which implements the threshold device signum function.
The second new item is the a-LMS (least mean square) algorithm, or learning law. This describes how to change the values of the weights until they produce correct answers. In a-LMS, the Adaline takes inputs, multiplies them by weights, and sums these products to yield a net. The binary output is +1 for net >=0 and -1 for net <0.
If the binary output does not match the desired output, the weights must adapt. Each weight will change by a factor of Dw (Equation 3) . The h is a constant which controls the stability and speed of adapting and should be between 0.1 and 1.0. Equation 4 shows the next step where the Dw's change the w's. Listing 3 shows a subroutine which performs both Equation 3 and Equation 4. Notice how simple C code implements the human-like learning.
Where do you get the weights? Originally, the weights can be any numbers because you will adapt them to produce correct answers. The weights make up the weight vector — another C array with the same number of elements as the input vector array.
The learning process consists of feeding inputs into the Adaline and computing the output using Listing 1 and Listing 2. If the output is incorrect, adapt the weights using Listing 3 and go back to the beginning. Figure 5 shows this idea using pseudocode.
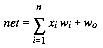
Dwi = hxi (target -net)
for i = o, n
Equation 4wi = wi +Dwi for i = o, nYou can use the Adaline to make another neural network — the multiple adaptive linear element or Madaline (Widrow and Lehr 1990) shown in Figure 6. The Madaline can solve problems where the data are not linearly separable such as shown in Figure 7. This is a graph of the heights and weights of professional football (+1) and basketball (--1) players. This is not as easy as linemen and jockeys, and the separating line is not straight (linear). Nevertheless, the Madaline will "learn" this crooked line when given the data.
The Madaline in Figure 6 is a two-layer neural network. The first layer contains hard limiting (+1 or --1) Adalines and the second layer is a single, fixed-logic element. Each Adaline in the first layer uses Listing 1 and Listing 2 to produce a binary output. The binary output passes on to a final decision maker that makes either an AND, OR, or MAJORITY decision. Listing 4 shows how to perform these three types of decisions.
The Madaline shown uses the Madaline 1 learning law instead of the a-LMS learning law. (There are three different Madaline learning laws, but we'll only discuss Madaline 1.) The Madaline 1 has two steps. First, give the Madaline data, and if the output is correct do not adapt. Second, if the output is incorrect, adapt (using Listing 3) the Adaline whose +1 or -1 output disagrees with the final answer and whose net (Equation 2) is closest to 0.
Suppose you have a Madaline with three Adalines and a MAJORITY decisionmaker. If the output should have been +1 and two of the Adalines produced --1's, use the a-LMS law and adapt the Adaline which produced a --1 and had a net closest to 0. Figure 8 shows the idea of the Madaline 1 learning law using pseudocode.
Once you have the Adaline implemented, the Madaline is easy because it uses all the Adaline computations. The only new items are the final decision maker from Listing 4 and the Madaline 1 learning law of Figure 8.
Using Neural Networks
There are three steps to using a neural network. First, input data with known correct answers. This can be tedious so you may want to write code which reads data from your favorite spreadsheet or database. Second, train the neural network using the learning law. This executes the learning-law code and requires no user interaction. Third, use the trained neural network on new data. You can enter one data point at a time or read it from a file.
The Adaline Program
Listing 5, Listing 6, Listing 7, and Listing 8 are complete programs that implement an Adaline and a Madaline neural network. I wrote these programs to be flexible enough to work many different problems, command-line driven, interactive, portable among compilers and operating systems, simple, and use a minimum amount of floating-point math.Listing 5 shows the main routine for the Adaline neural network. The routine interprets the command line and calls the necessary Adaline functions. The command line is
adaline inputs-file-name
weights-file-name
size-of-vectors mode
The mode is either input, training, or working to correspond to the three steps to using a neural network. main uses the malloc function to allocate space for the input and weight arrays. This gives you flexibility because it allows different-sized vectors for different problems. The vectors are not floats so most of the math is quick-integer operations.Listing 6 shows the functions which implement the Adaline. The first three functions obtain input vectors and targets from the user and store them to disk. These functions implement the input mode of operation. The next two functions display the input and weight vectors on the screen. These are useful for testing and understanding what is happening in the program.
Next in Listing 6 is train_the_adaline. This performs the training mode of operation and is the full implementation of the pseudocode in Figure 5. train_the_adaline calls the next four functions of Listing 6 as it loops through the input vectors and tests for correct answers. If the answers are incorrect, it adapts the weights.
The next functions in Listing 6 resemble Listing 1, Listing 2, and Listing 3. These calculate Adaline outputs and adapt the weight vector. There is nothing difficult in this code. The final function in Listing 6 is process_new_case. This is the working mode for the Adaline. You call this when you want to process a new input vector which does not have a known answer. process_new_case uses the other functions in Listing 6 to obtain the new input vector, calculate the answer, and display it.
Believe it or not, this code is the mystical, human-like, neural network. It can "learn" when given data with known answers and then classify new patterns of data with uncanny ability.
Adaline Example
Figure 4 showed a simple classification problem involving football linemen and horse-racing jockeys. Table 1 lists the height, weight, and classifications of the data. The first step is to enter the data. The command is
adaline adi adw 3 iThe file names adi and adw can be anything you want. The program prompts you for data and you enter the 10 input vectors and their target answers. I entered the heights in inches and the weights in pounds divided by 10. This made the weights the same magnitudes as the heights. If your inputs are not the same magnitude, then your weights can go haywire during training.
The next step is training. The command is
adaline adi adw 3 tThe program loops through training and prints the results to the screen. For this case, the weight vector was (--21 --1840 --664). If you use these numbers and work through the equations and the data in Table 1, you will have the correct answer for each case. The final step is working with new data. The command is:
adaline adi adw 3 wThe program prompts you for a new input vector and returns the class (+1 or --1) it calculates. If you enter a height and weight similar to those given in Table 1, the program should give a correct answer. However, with only 10 input vectors for training, it is likely that a height and weight entered will produce an incorrect answer. The more input vectors you use for training, the better trained the network. Ten input vectors is not enough for good training. Use more data for better results.
The Madaline Program
Listing 7 shows the main routine of the Madeline program. The command line is
madaline inputs-file-name
weights-file-name
size-of-vectors
number-of-adalines
mode choice-type
The new parameters are the number of Adalines to use and the mode (AND, OR, or MAJORITY). The code resembles Adaline's main program. Here, the weight vector is two-dimensional because each of the multiple Adalines has its own weight vector. The remaining code matches the Adaline program as it calls a different function depending on the mode chosen.Listing 8 shows the new functions needed for the Madaline program. The function train_the_madaline implements the pseudocode shown earlier in Figure 8. This function loops through the input vectors, loops through the multiple Adalines, calculates the Madaline output, and checks the output. If the output does not match the target, it trains one of the Adalines. This function is the most complex in either program, but it is only several loops which execute on conditions and call simple functions. Notice how it uses several of the Adaline functions given in Listing 6 (calculate_net, calculate_output, train_weights). This reflects the flexibility of those functions and also how the Madaline uses Adalines as building blocks.
The next function, madaline_output, resembles Listing 4. It calculates the final Madaline output using either the AND, OR, or MAJORITY method. which_adaline, in Listing 8, chooses which Adaline to adapt. You want the Adaline that has an incorrect answer and whose net is closest to zero.
The final function is process_new_madaline. This implements the working mode of the Madaline and resembles process_new_case in Listing 6. process_new_madaline obtains the new input vector from the user, calculates the Adaline outputs, and calculates the Madaline output.
Madaline Example
Figure 7 showed another height vs. weight graph using football and basketball players. The dividing line is crooked (non-linear). This is beyond the ability of a single Adaline. Table 2 shows the input vectors and their correct classifications. The first step is to input these vectors using the command line
madaline bfi bfw 2 5 i mThe file names bfi and bfw are arbitrary. I chose five Adalines, which is enough for this example. You should use more Adalines for more difficult problems and greater accuracy. You will need to experiment with your problems to find the best fit. I chose the MAJORITY Madaline decisionmaker. Again, experiment with your own data.
The program prompts you for all the input vectors and their targets. I entered the height in inches and the weight in pounds divided by ten to keep the magnitudes the same. Next is training and the command line is
madaline bfi bfw 2 5 t mThe program loops through the training and produces five each of three element weight vectors.
Now it is time to try new cases. The command line is
madaline bfi bfw 2 5 w mThe program prompts you for a new vector and calculates an answer. This is a more difficult problem than the one from Figure 4. Therefore, it is easier to find an input vector that should work but does not, because you do not have enough training vectors. Ten or 20 more training vectors lying close to the dividing line on the graph of Figure 7 would be much better.
Another Madaline Example
Recognizing a handwritten character is vastly different from the previous example, but the Madaline program will do it without changing any source code. You will train the Madaline to recognize whether or not a handwritten character is a capital A. Figure 9, Figure 10, and Figure 11 show how I created input vectors for training the Madaline. I made a 9x7 matrix, wrote an A by hand, and blocked off the A into the squares. This is one input training vector containing 63 elements (see Table 3) . Each element of the vector is either a 1 or 0 and the target output is + 1 for an A and -1 for anything else. I sketched out six A's, one B, one E, and one garbage input vector. I entered all of these long vectors by hand using the command
madaline ai2 aw2 63 5 i mI trained the Madaline using:
madaline ai2 aw2 63 5 t mI tried new cases using:
madaline ai2 aw2 63 5 w mThe Madaline correctly identified several more A's and non-A's that I sketched and entered. This demonstrates how you could recognize handwritten characters or other symbols with a neural network . It would be nicer to have a hand scanner, scan in training characters, and read the scanned files into your neural network. That would eliminate all the hand-typing of data.
These examples illustrate the types and variety of problems neural networks can solve. The heart of these programs is simple integer-array math. They execute quickly on any PC and do not require math coprocessors or high-speed 386's or 486's
Do not let the simplicity of these programs mislead you. They implement powerful techniques. The splendor of these basic neural network programs is you only need to write them once. You can apply them to any problem by entering new data and training to generate new weights. Practice with the examples given here and then stretch out.
References
Widrow, Bernard and Michael A. Lehr. September 1990. "Thirty Years of Adaptive Neural Networks: Perceptron, Madaline, and Backpropagation," Proceedings of the IEEE.