John Forkosh has an MS in physics, and for the past ten years has been an independent consultant working primarily under VAX/VMS in C. He developed the algorithm discussed in this article while at the Goddard Institute for Space Studies in New York City, working on the radiative transfer code for a general circulation model of the earth's atmosphere (used to study climatic change, particularly due to increased carbon dioxide resulting from burning fossil fuels). Readers may contact him at 285 Stegman Parkway #309, Jersey City, NJ 07305.
Scientific applications often require the very frequent evaluation of complicated functions. To reduce computational overhead, you can define such a function using a table of its values at various fixed points. You then need some form of interpolation to estimate values of the function at intermediate points. Linear interpolation is the quickest procedure. Unfortunately, it is also usually the least accurate.
A lookup table for a function f(x) is a sequence of numbers yi=f(xi), i=1...n. Using linear interpolation, you approximate f(x) by straight-line segments connecting the yis. Consider the simple function f(x)=x2. Because this function is concave (its second derivative f"(x)=2 is always positive) the straight line segments will always lie above the curve (i.e., linearly interpolated values will always be too large).
You can avoid such systematic errors by using line segments connecting a sequence of "pseudo-values" yi* that you determine by minimizing the sum of the integrated square-errors attributable to each segment. A least-squares technique determines the appropriate yi*s. The result is that the table does not contain exact values for the function f(x) at the points xi. However, it minimizes the mean-square error due to sampling random points in the function's domain. For instance, for f(x)=x2 in the interval -10<=x<=10 with table values at each integer, the mean square error is reduced by a factor of 6 (the rms error by a factor of 2.45).
This discussion is pitched at about the level of Numerical Recipes in C (Cambridge University Press, 1988). It illustrates not only interpolation (Chapter 3), but also least squares (Chapter 14) and the solution of linear algebraic equations (Chapter 2). The latter arises because, for a table with n values, our analysis expresses the yi*s as n simultaneous equations in terms of the yis. This article provides complete code so that you can apply the algorithm to any function f(x) whatsoever.
Functions Of A Single Variable
Interpolation techniques represent a function y=f(x) by a table of values yi=f(xi), i=1...n. Between yi and yi+1, standard linear interpolation approximates f(x) by a line segment, which I'll denote by ui(x)=aix+bi, xi<=x<=xi+1, with ai and bi chosen so that ui(xi)=yi and ui(xi+1)=yi+1. This provides exact values of f(x) at the xis, but it does not constrain the mean square errors:In addition, it gives rise to systematic errors when the sign of f"(x) doesn't change between points. If f">0 (concave function) then u-f>0 for all x in the interval (and similarly for a convex function). This situation is illustrated in Figure 1a.
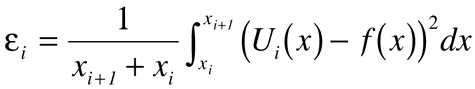
Figure 1b illustrates the procedure to be developed. In this case, the line segments ui(x) connect points ui(xi)=yi* and ui(xi+1)=yi+1*. The yi*s are determined by a least squares technique that minimizes the sum of the error terms given in Equation 1, so that:
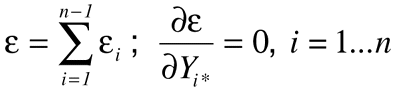
This gives n equations for the n unknown yi*s.
The hard work is doing all the algebra necessary to formulate these n equations so that you can program their solution. To keep the analysis tractable, assume that xi+1-xi=Dx is constant. Then the line segments can be written as in Equation (a) (Equation 3) .
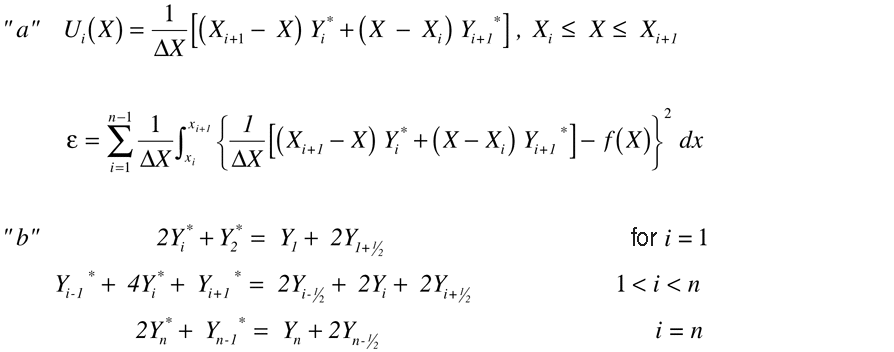
Equation 3 gives the sum of the error terms given by Equation 1 and Equation 2.
At the interior points 1<i<n, two terms from the sum in Equation 3 contain subscript i, so that:
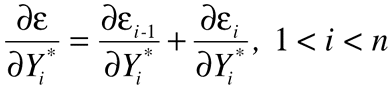
while at the boundaries i=1 and i=n, only one term contributes, so that:
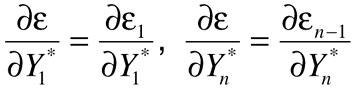
You can evaluate these derivatives directly. After evaluating them and making several substitutions of variables, you get:
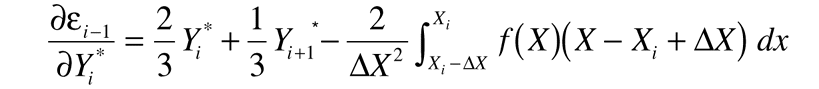
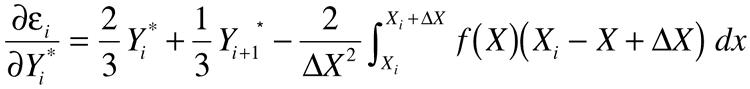
So far the analysis is exact. To finish the problem, approximate the right-hand integrals using Simpson's rule applied at the midpoint of each interval. Let yi±½=f(x±½Dx) so that:
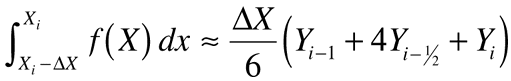
from which we can evaluate:
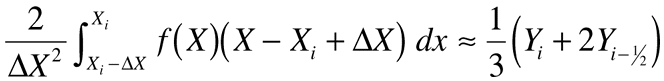
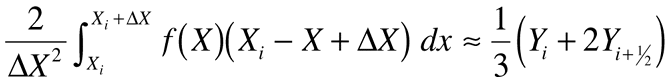
You can obtain any desired degree of accuracy by using better approximations in Equation 6. Substitute the results back into Equation 5, and in this case:
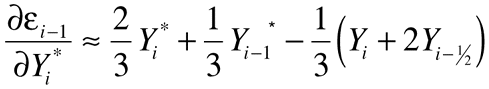
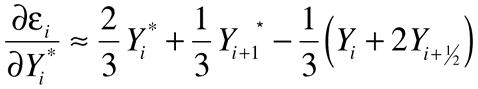
Equation 2, Equation 4, and Equation 7 now let you write down n equations for the n unknown yi*s in terms of the known yis (see equation (b) in Equation 3) .
These results are most easily written in matrix form:
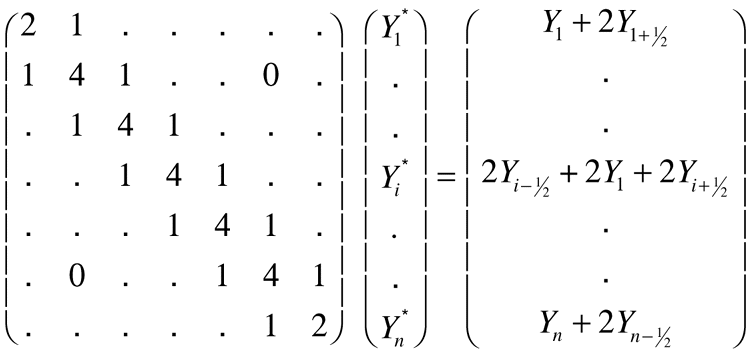
Equation 8 specifies how to construct a table of y*s, for linearly interpolating any function f(x), that minimizes (modulo Simpson's rule) the mean-square error due to randomly sampling points in the function's domain. However, f(x) must be a function of a single variable. The application for which this algorithm was originally designed requires interpolation of a function z=f(x,y) of two variables. This more general situation is conceptually quite similar to the one-dimensional case discussed. The required algebra, however, becomes noticeably more complicated. I therefore decided to stop the formal discussion of the algorithm at this point.
Discussion Of Code
Listing 1 and Listing 2 show the implementation of Equation 8. Listing 1 contains a C function lint1d(x0,dx,n,f,y) that returns a table of y*s, suitable for one-dimensional linear interpolation, as prescribed by Equation 8. It simply mallocs a temporary nxn array in which the coefficient matrix is set up, then calls the user-supplied function f to initialize array y with the vector of constants,. Finally, it solves the simultaneous equations, returning the y* solutions to the caller in the same array y. Listing 1 also contains a test driver for lint1d. Some sample output for f(x)=x2 as discussed in the introduction is shown in Figure 3.Listing 2 contains the simultaneous equation solver used by lint1d. It's a Fortran-to-C port of an old IBM Scientific Sub-routine Package routine, simq, as noted in the code. As you can see, Equation 8 specifies a very straightforward procedure, and the resulting code for lint1d is correspondingly simple. The code for simq is a bit dense, but can be treated as a black box for the purposes of this application.
By supplying the address of your own function as the argument f to lint1d, an interpolation table can very easily be constructed to suit any purpose whatsoever. Thus, almost any application that employs one-dimensional linear interpolation at fixed intervals should be able to realize noticeable improvements in accuracy, through a simple one-line call to lint1d. Afterwards, interpolation on the improved table is performed transparently and requires no application-level recoding.
Both listings contain embedded drivers (that are compiled when the #defined flag TESTDRIVE is true) to facilitate module-evel testing and to illustrate usage. I've also tried to carefully document the code (except for some of the more elaborate indexing arithmetic required near the bottom of simq). My experience with scientific code is that it frequently tends to be under-documented and also under-robust. The latter problem can be particularly pernicious since the code usually won't blow up but will simply supply the wrong result due to an inappropriate numerical method or due to some more trivial problem. (For instance, I once worked on a model where the value of p had been entered incorrectly.) Because numerical results are usually not analytically verifiable, and because feedback mechanisms frequently prevent small errors from growing uncontrollably, a researcher may not realize that the results are little more than massaged noise. You can effectively guard against such difficulties by using a design that carefully decomposes a complicated calculation into easily describable functional components that can be individually tested for known correct results.
Note: Figure 2 has been replaced with Equation 3.