Richard, an oncologist on the faculty of the Ohio State University, is director of developmental therapeutics for the OSU Comprehensive Cancer Center. He can be reached at gams.1@osu.edu.
As a physician who cares for cancer patients, I have been conducting clinical trials of anticancer drugs for almost 30 years. During these trials, a group of investigators must agree on a uniform therapy strategy for a large number of patients. For example, if a patient's blood count is lowered as a side effect of the treatment, some investigators might want to delay the next treatment for a week or two; others might want to treat as scheduled, but with a lower dose. We must agree to do one or the other, and this agreement, along with all the other details of the treatment, is formalized in a document called a "protocol."
Reading a complex protocol is time consuming and often confusing. Achieving protocol compliance is a major obstacle to a successful clinical trial. One approach we have taken has been to develop rule-based expert systems that incorporate the rules of the protocol. These systems are written in Prolog and/or C++ and run under various Microsoft Windows platforms. When a patient is being considered for a course of therapy, the system is "consulted," resulting in proper adherence to protocol.
The results of all therapy are recorded. This record serves as the basis for further treatment decisions as well as for analyzing the results of the therapy for both the individual patient and the entire study population. We can compare the results to determine which treatment has the greatest efficacy with the least toxicity (and of course, cost).
This data is naturally hierarchical. At each level, one data item may be viewed as owning or being related to several subsidiary data items. For example, a clinical study has a number of patients enrolled, and each patient might receive multiple cycles or courses of treatment. In each treatment cycle, drugs may be administered, vital signs measured, laboratory tests obtained, and toxicities experienced. Of the universe of possible measurements, we must create an adequate subset that shows the therapy to be safe and effective.
Some observations lend themselves to logical grouping. For instance, a complete blood count (CBC) consisting of hemoglobin, hematocrit, white-blood count, and the like, would be one record type. Other data such as the patient's age, sex, and visits (number, date) would require a separate record type (table). There are many patients involved in large studies. One study included 1500 patients treated according to two treatment plans at over 50 separate hospitals worldwide. We must find efficient ways to handle this copious and diverse information.
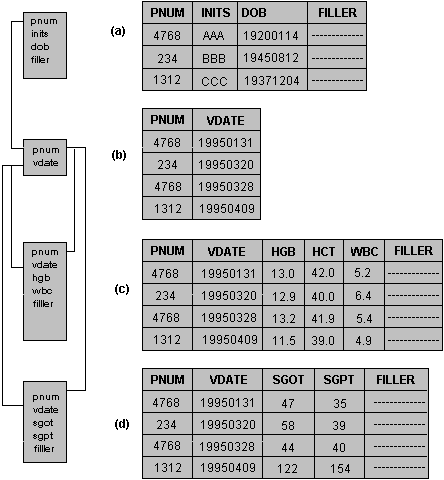
Many (if not most) large database systems employ the relational model, in which the data are viewed as a series of tables, much like individual spreadsheets. Each column of the table represents an attribute (such as the patient's age), and each row represents one record with a value (or NULL) for each attribute. Relationships are represented by shared columns in two or more tables. Often, one table's value is considered the primary key, while the identical value in another table is the foreign key. When data from both tables are requested, the tables are "joined" through these keys, as shown in Figure 1. The SQL specification used to generate this database is shown in Listing One. However, there is far more to the relational model than these simple concepts.
The primary and foreign keys in each table need to be indexed for acceptable join performance. For example, to see the visit-three hemoglobin for each patient in the study, we need to join the patient, visit, and CBC tables through the primary and foreign keys. If these keys were not indexed, the query engine would have to walk through entire tables over and over again to see whether a visit record were associated with a particular patient and whether a CBC record "belonged" to that visit. Indexes expedite the process of identifying related records.
For some time, we've felt that the relational model is inappropriate for large volumes of data of many different types (clinical information, for example). Such data require multiple tables (each representing a different data group) and indexes for all primary and foreign keys. Performance is hampered by the two-stage lookup for relational links: First, we look up the index to find a key value, then we navigate to the actual record in the data table and read the information. Furthermore, primary and foreign keys are repeated in each table and index in which they are referenced, creating data redundancy.
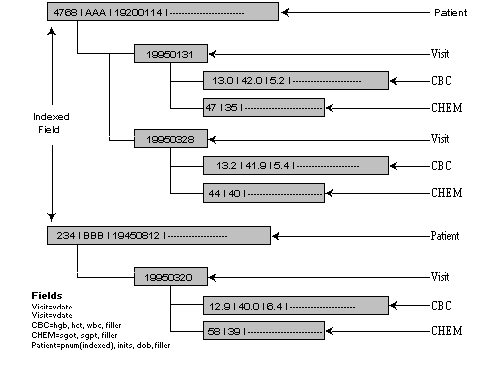
An alternative is the network model. In this model, records still represent each data type or group, but related records are connected by direct pointers (database addresses). One record is considered the owner, and the other record, the member. Each record may own or be owned by many types of records, providing a natural way to express one-to-many (hierarchical) and many-to-many (network) relationships.
Indexes are optional in this model and are often needed only for rapid navigation to the primary-key value in a particular record type. For example, we may wish to find an individual patient from among all patients in a study. Once the patient is located, other data may be found by direct navigation through sets. Each set consists of an owner and one or more member record types. Such a model results in data being "hashed" into logical groups. Linear traversal through such a group is quite efficient. The sample database organized in such a model is shown in Figure 2. Listing Two is the data definition language (DDL) file for this schema.
We have found network/hierarchical databases especially suitable for managing clinical-trial data. There is little need for indexes, since navigation is accomplished through direct links from an owner to members in sets. Performance is enhanced by direct pointer lookup, resulting in improved access speed. Such pointers allow speedy navigation from owner to members and vice versa. Furthermore, data is stored only once: There is no need for redundant storage as primary/foreign keys or duplicating data in indexes.
We use the Raima Data Manager (RDM) to implement the network model. RDM is a database engine for C programmers that includes a manager, SQL-based query system, and database restructure program. The tool provides relational B-tree indexing, network-database model, multiple-database access, built-in referential integrity, record- and file-locking functions, automatic recovery, and a relational query and report writer. Although RDM has been reliable and efficient, we recognize a number of drawbacks. While available on multiple platforms, RDM is implemented solely as a peer-to-peer system. Furthermore, it isn't scalable in the sense of providing tools for very large data sets or distributed databases.
On the benefit side, RDM has a very usable API with a C/C++ interface. We often require record-by-record data access, and RDM provides this somewhat more readily than do SQL cursors. Furthermore, the RDM API has been encapsulated in the Raima Object Manager (ROM), a C++ interface that provides object persistence and object-relationship management. ROM lets you encapsulate object storage and database navigation into C++ class definitions. Unfortunately, RDM provides limited query tools. Raima has put a "relational" face on its network database with db_Query, a tool that provides SQL access to RDM. However, it is only a limited SQL subset and doesn't interface with standards such as ODBC.
We're also using Raima's Velocis, a database engine for building client/server applications for DOS, Windows, Windows NT, OS/2, NetWare, and UNIX. The engine is compliant with the 1989 ANSI SQL standard and provides an ODBC Level 1 interface with several Level 2 features. It has a number of unique features including the ability to extend the database with C/C++ "extension modules" that permit portions of the program to reside on the server rather than on the client. This is important to us, since it is essential that everyone work from the same protocol rules. Protocols are frequently revised, and, although some rules may be expressed as database record values, others must be coded. With extension modules, we can keep the protocol logic in one place rather than having to upgrade all the clients. (In the usual database context, this permits business rules to reside in one place rather than be distributed throughout the organization.) We have implemented Velocis on a Windows NT server using 16-bit Windows for Workgroup clients, but we will soon move to 32-bit Windows 95/NT clients. In addition, Velocis is available as a stand-alone Windows 3.x system.
Velocis uses the same data-file structure as RDM, so we can continue using existing RDM data files. Additionally, Velocis may be accessed through ROM (or the lower-level RDM API), so we can use existing RDM programs with a simple recompile. Velocis can also be accessed through an ODBC interface, so we can use a variety of query tools and report generators. We may modify the database using ROM and query it using an ODBC-compliant tool.
An interesting feature of Velocis is the implementation of virtual foreign keys. Instead of joining tables through traditional relational links using primary and foreign keys, joins can optionally be implemented as pointers (as in the network model). This would eliminate the need for indexes on foreign keys, which would be accessed directly through pointers. Data would not be stored for foreign keys, but instead retrieved from the primary table through pointers. This could yield the space and speed advantage of RDM while providing an ANSI-compliant SQL interface. Listing Three presents the modified SQL specification employing virtual foreign keys. The CREATE INDEX statement for the visit, CBC, and CHEM tables have been replaced by CREATE JOIN statements.
To test this feature, I generated two databases with Velocis--the traditional, relational model in Listing One and the model using virtual foreign keys in Listing Three. Using ODBC, I then inserted 10,000 patient records into each database. The patient numbers were taken sequentially from an array of 10,000 integers that had been shuffled to produce a pseudorandom distribution of values. I then inserted ten visits into every hundredth patient, again in random sequence. Each visit was associated with a CBC and a CHEM record. Finally, I performed the query shown in Example 1(a), which joined all the tables for each of the patients who had associated visit, CBC, and CHEM records. The question mark at the end of the query is a placeholder for a value supplied at run time, permitting the program to loop through the patients and perform the query on each. All of these tests were performed using the stand-alone version of Velocis. Programs were compiled as QuickWin applications in Microsoft Visual C++ Version 1.52 on a Windows NT 3.51 workstation. Table 1 shows the results of these tests.
The time to insert 10,000 patient records into each of the databases was approximately the same. The default for Velocis is to place each data record and each key in its own file. The file containing the patient records was larger in the database set up to have virtual foreign keys, since space had to be allotted for the direct links to the foreign tables. I was disappointed that the visit, CBC, and CHEM record inserts took 25 percent longer (5.5 versus 4.5 minutes) for the virtual-foreign-key insertion. In addition, the total file size was more than 11 percent larger. I assume these differences are due to the bookkeeping necessary to maintain the direct links.
Virtual foreign keys performed much better during queries. The selection of data from the joined tables took 13 seconds versus 2.5 minutes in the traditional model. To be certain that the problem was not with the ODBC interface, I used Raima's interactive query tool to perform the query in Example 1(b). The query took 52 seconds using the traditional model and six seconds using virtual foreign keys.
Velocis provides an efficient implementation of the relational model in a client/ server database. A unique feature is that it is based on a network data structure, permitting pointer access to related records. While this doesn't reduce the size of the data store and may ultimately hurt bulk insertion speed, it enables extremely rapid retrieval of joined records. For situations with a very large number of record types, Velocis provides a fully SQL-compliant database with efficient query capability. Our long-range plan is to use the ROM object-oriented interface for programmatic interaction with our data, but employ ODBC tools for query and report generation.
Raima Database Manager 4.0
Raima Object Manager 3.0
Velocis 1.3
Raima Corp.
1605 NW Sammamish Road Suite 200
Issaquah, WA 98027
800-275-4724
(a) "SELECT PNUM, VDATE, HGB, SGOT FROM PATIENT, VISIT, CBC, CHEM WHERE PATIENT.PNUM = VISIT.PNUM AND VISIT.PNUM = CBC.PNUM AND VISIT.VDATE = CBC.VDATE AND VISIT.PNUM = HEM.PNUM AND VISIT.VDATE = CHEM.VDATE AND PNUM = ?" (b) SELECT PNUM, VDATE, HGB FROM PATIENT, VISIT, CBC WHERE PATIENT.PNUM = VISIT.PNUM AND VISIT.PNUM = CBC.PNUM AND VISIT.VDATE = CBC.VDATE AND PNUM IN (260, 445, 526, 534) ORDER BY PNUM;
Indexed Virtual
Foreign Keys Foreign Keys
Size of patient records (bytes) 688,128 819,200
Size of all data (including index) 1,146,880 1,277,952
Time to insert patients (minutes) 11:56 12:31
Time to insert visits 04:26 05:23
Time to query (ODBC) 02:21 00:13
Time to query (interactive) 00:52 00:06
create database clin1 on clindev1;
create table patient
(
pnum smallint primary key
"patient number",
inits char(4)
"initials",
dob long
"date of birth",
filler char(40)
"just to add length to record"
);
create unique index pnum_key on patient(pnum);
create table visit
(
vdate long not null
"visit date",
pnum smallint not null references patient(pnum),
primary key(pnum, vdate)
);
create unique index visit_key on visit(pnum, vdate);
create table cbc
(
pnum smallint not null,
vdate long not null,
hgb float "hemoglobin",
hct float "hematocrit",
wbc float "white blood count",
filler char(20),
foreign key(pnum, vdate) references visit(pnum, vdate)
)
create index cbc_key on cbc(pnum, vdate);
create table chem
(
pnum smallint not null,
vdate long not null,
sgot float "liver enzyme",
sgpt float "liver enzyme",
filler char(20),
foreign key(pnum, vdate) references visit(pnum, vdate)
);
create index chem_key on chem(pnum, vdate);
database clin {
data file file000_patient = "clin.000" contains patient;
key file ndx000_pnum_key = "clin.001" contains pnum_key;
data file file001_visit = "clin.002" contains visit;
data file file00_cbc = "clin.003" contains cbc;
data file file003_chem = "clin.004" contains chem;
key file ndx000_key00101_visit = "clin.005" contains key00101_visit;
record patient {
short pnum;
char inits[5];
long dob;
char filler[41];
compound unique key pnum_key {
pnum asc;
}
}
record visit {
long vdate;
short pnum;
compound unique key key00101_visit {
pnum asc;
vdate asc;
}
}
record cbc {
double hgb;
double hct;
double wbc;
char filler[21];
}
record chem {
double sgot;
double sgpt;
char filler[21];
}
set visit_set {
order last;
owner patient;
member visit;
}
set cbc_set {
order last;
owner visit;
member cbc;
}
set chem_set {
order last;
owner visit;
member chem;
}
}
create database clin2 on clindev2;
create table patient2
(
pnum2 smallint primary key
"patient number",
inits2 char(4)
"initials",
dob2 long
"date of birth",
filler2 char(40)
"just to add length to record"
);
create unique index pnum2_key on patient2(pnum2);
create table visit2
(
vdate2 long not null
"visit2 date",
pnum2 smallint not null references patient2(pnum2),
primary key(pnum2, vdate2)
);
create join visits on visit2(pnum2);
create table cbc2
(
pnum2 smallint not null,
vdate2 long not null,
hgb2 float "hemoglobin",
hct2 float "hematocrit",
wbc2 float "white blood count",
filler2 char(20),
foreign key(pnum2, vdate2) references visit2(pnum2, vdate2)
)
create join cbc on cbc2(pnum2, vdate2);
create table chem2
(
pnum2 smallint not null,
vdate2 long not null,
sgot2 float "liver enzyme",
sgpt2 float "liver enzyme",
filler2 char(20),
foreign key(pnum2, vdate2) references visit2(pnum2, vdate2)
);
create join chems on chem2(pnum2, vdate2);
End Listings
{kind=link}
{kind=link}