Listing One
void EXPORT Integral::Evaluate() {
// We use this constant to divide the interval into two equal parts:
const long double ldHalf = 0.5e0L;
// Note that the maximum possible error is:
// -(1,346,350/326,918,592)*h^13*epsilon, where epsilon is some value
// of the 12th derivative of the supplied function in our sub-interval.
// See "Handbook of Mathematical Functions" by Abramowitz and Stegun,
// formula 25.4.20 on page 887.
// Empirically derived for long double stepsize:
const long double ldStepsizeForBestAccuracy = 0.01e0L;
// The stepsize used for the integral estimation
// The number .1 is due to the 11 terms in the Newton-Cotes formula
// creating 10 sub-intervals.
const long double ldH = ( ldX1 - ldX0 )*0.1e0L;
// If stepsize is too large, divide the integral into two equal sections.
if ( ldH > ldStepsizeForBestAccuracy ) {
long double ldMidpoint = ldX0 + ( ldX1 - ldX0 )*ldHalf;
Integral i0( ldX0, ldMidpoint, ldFprime, pldConstArray );
Integral i1( ldMidpoint, ldX1, ldFprime, pldConstArray );
ldIntegralResult=i0.ldGetIntegralResult()+i1.ldGetIntegralResult();
}
else { // Newton-Cotes constant for calculating the integral:
const long double A = 5.0e0L/299376.0e0L;
// Perform the summation.
ldIntegralResult = (
16067e0L * ( ldFprime( ldX0, pldConstArray )
+ldFprime( ldX0 + ldH*10, pldConstArray ) )
+ 106300e0L * ( ldFprime( ldX0 + ldH, pldConstArray )
+ldFprime( ldX0 + ldH*9, pldConstArray ) )
- 48525e0L * ( ldFprime( ldX0 + ldH*2, pldConstArray )
+ldFprime( ldX0 + ldH*8, pldConstArray ) )
+ 272400e0L * ( ldFprime( ldX0 + ldH*3, pldConstArray )
+ldFprime( ldX0 + ldH*7, pldConstArray ) )
- 260550e0L * ( ldFprime( ldX0 + ldH*4, pldConstArray )
+ldFprime( ldX0 + ldH*6, pldConstArray ) )
+ 427368e0L * ldFprime( ldX0 + ldH*5, pldConstArray )
) * ldH * A;
}
}
Listing Two
void EXPORT Integral::Evaluate() {
// We use this constant to divide the interval into two equal parts:
const long double ldHalf = 0.5e0L;
// Empirically derived for long double stepsize: The number .21 is due to
// the 22 weights in our Gaussian formula creating 21 subdivisions. This
// will give a stepsize of .01, when .21 is divided 21 times.
// Theoretically, the error should be less than that of Newton-Cotes.
const long double ldSmallEnoughInterval = 0.21e0L;
// If interval is too large, divide the integral into two equal sections.
if ( ( ldX1 - ldX0 ) > ldSmallEnoughInterval ) {
long double ldMidpoint = ldX0 + ( ldX1 - ldX0 )*ldHalf;
Integral i0( ldX0, ldMidpoint, ldFprime, pldConstArray );
Integral I1( ldMidpoint, ldX1, ldFprime, pldConstArray );
ldIntegralResult = i0.ldGetIntegralResult() + I1.ldGetIntegralResult();
}
else
ldIntegralResult = ldGaussian( ldFprime, ldX0, ldX1, pldConstArray );
}
// Internal Method, Gaussian rule for integral evaluation:
static long double ldGaussian(_ldIntegralFunction_t ldF,
long double ldA, long double ldB, long double *pldConstArr) {
const long double ldGLWeights[] = {
2.78342835580868333037e-002L, 6.27901847324523123016e-002L,
9.31451054638671257124e-002L, 1.16596882295995240001e-001L,
1.31402272255123331128e-001L, 1.36462543388950315360e-001L,
1.31402272255123331128e-001L, 1.16596882295995240001e-001L,
9.31451054638671257124e-002L, 6.27901847324523123016e-002L,
2.78342835580868333037e-002L,
};
const long double ldGLAbscissae[] = {
1.08856709269715036124e-002L, 5.64687001159523504590e-002L,
1.34923997212975337962e-001L, 2.40451935396594092037e-001L,
3.65228422023827513853e-001L, 5.00000000000000000000e-001L,
6.34771577976172486147e-001L, 7.59548064603405907963e-001L,
8.65076002787024662065e-001L, 9.43531299884047649541e-001L,
9.89114329073028496360e-001L,
};
long j; /* Array index */
long double ldXOffset; /* X scale factor for the interval */
long double ldSum; /* Partial summation term */
long double ldCenter = ( ldB + ldA ) * 0.5; /* Average of b and a */
long double ldH = ( ldB - ldA ) * 0.5; /* Half the width of the interval */
long double ldIntegralResult = 0.0e0L;
for ( j = 0; j < 11; j++ ) {
/* Calculate f(x) at two symmetrical offsets from the center: */
ldXOffset = ldH * ldGLAbscissae[j];
ldSum = ( *ldF )( ldCenter - ldXOffset, pldConstArr ) +
( *ldF )( ldCenter + ldXOffset, pldConstArr );
ldIntegralResult += ldGLWeights[j] * ldSum;
}
return ( ldIntegralResult * ldH );
}
Listing Three
#define HALF_KNOT_COUNT 21
#define ABS( a ) ( a ) > 0 ? ( a ) : -( a )
void EXPORT Integral::Evaluate() {
// Empirically derived for long double stepsize: const long double ldSmallEnoughInterval = 0.25e0L;
// If interval is too large, divide the integral into two equal sections.
if ( ( ldX1 - ldX0 ) > ldSmallEnoughInterval ) {
long double ldMidpoint = ldX0 + ( ldX1 - ldX0 ) * 0.5e0L;
Integral i0( ldX0, ldMidpoint, ldFprime, pldConstArray );
Integral I1( ldMidpoint, ldX1, ldFprime, pldConstArray );
ldIntegralResult=i0.ldGetIntegralResult()+I1.ldGetIntegralResult();
}
else {
const long double ldTol = LDBL_EPSILON*2.0e0L;
int I1 = -1;
int I2 = -1;
long double pldVectorOne[HALF_KNOT_COUNT] = { 0 };
long double pldVectorTwo[HALF_KNOT_COUNT] = { 0 };
int iRuleChoice = 0;
long double ldResult0;
long double ldResult1;
ldResult0 = qxrul( ldFprime, ldX0, ldX1, iRuleChoice++, pldConstArray,
pldVectorOne, pldVectorTwo, &I1, &I2 );
ldResult1 = qxrul( ldFprime, ldX0, ldX1, iRuleChoice++, pldConstArray,
pldVectorOne, pldVectorTwo, &I1, &I2 );
if ( ABS( ( ldResult0 - ldResult1 )/ldResult1 ) > ldTol ) {
ldResult0 = ldResult1;
ldResult1 = qxrul( ldFprime, ldX0, ldX1, iRuleChoice++, pldConstArray,
pldVectorOne, pldVectorTwo, &I1, &I2 );
if ( ABS( ( ldResult0 - ldResult1 )/ldResult1 ) > ldTol )
ldResult1 = qxrul( ldFprime, ldX0, ldX1, iRuleChoice,
pldConstArray, pldVectorOne, pldVectorTwo, &I1, &I2 );
}
ldIntegralResult = ldResult1;
}
}
/* These routines are derived from function QXRUL from:
** ALGORITHM 691, COLLECTED ALGORITHMS FROM ACM.
** THIS WORK PUBLISHED IN TRANSACTIONS ON MATHEMATICAL SOFTWARE,
** VOL. 17, NO. 2, PP. 218-232. JUNE, 1991.
** This was a component of the SLATEC FORTRAN library created by:
** LAWRENCE LIVERMORE NATIONAL LABORATORY
** To compute I = integral of f() over ( ldA, ldB ), with error estimate
** Parameters on entry:
** f() - long double function to be integrated
** ldA - long double lower limit of integration
** ldB - long double upper limit of integration
** iRuleChoice - int
** Selector for choice of local integration rule. Rule used with:
** 13 points if iRuleChoice = 0, 19 points if iRuleChoice = 1,
** 27 points if iRuleChoice = 2, 42 points if iRuleChoice = 3
** pldVectorOne - long double
** vector containing pI1 saved functional values of positive abscissas.
** pldVectorTwo - long double
** vector containing pI2 saved functional values of negative abscissas.
** pI1, pI2 - int number of elements in pldVectorOne, pldVectorTwo respectively.
** On return ** ldY - long double approximation to the integral I.
** pldVectorOne - long double
** vector containing pI1 saved functional values of positive abscissas.
** pldVectorTwo - long double
** vector containing pI2 saved functional values of negative abscissas.
** pI1, pI2 - int number of elements in pldVectorOne,pldVectorTwo respectively.
*/
static long double qxrul(_ldIntegralFunction_t ldF, long double ldA,
long double ldB, int iRuleChoice, long double *pldConstArray,
long double *pldVectorOne, long double *pldVectorTwo,
int *pI1, int *pI2) {
/* Starting positions into the weights array: */
int iStart[] = { 0, 7, 17, 31 };
/* Lengths of the weight sequence to process: */
int iLen[] = { 7, 10, 14, HALF_KNOT_COUNT };
/* Symmetrical offsets +/- for unit interval */
const long double ldAbscissae[HALF_KNOT_COUNT] = {
0.0000000e0L, 0.2500e0L, 0.5000e0L, 0.750000e0L, 0.87500e0L,
0.9375000e0L, 1.0000e0L, 0.3750e0L, 0.625000e0L, 0.96875e0L,
0.1250000e0L, 0.6875e0L, 0.8125e0L, 0.984375e0L, 0.18750e0L,
0.3125000e0L, 0.4375e0L, 0.5625e0L, 0.843750e0L, 0.90625e0L, 0.9921875e0L
};
const long double ldWeights[52] = { // Shortened to 25 digits for printing
0.1303262173284849021810473e0L, 0.2390632866847646220320330e0L,
0.2630626354774670227333506e0L, 0.2186819313830574175167853e0L,
0.0275789764664283686585960e0L, 0.1055750100538458443365035e0L,
0.0157119426059518225416843e0L, 0.1298751627936015783241174e0L,
0.2249996826462523640447835e0L, 0.1680415725925575286319047e0L,
0.1415567675701225879892812e0L, 0.1006482260551160175038684e0L,
0.0251060486072428247905834e0L, 0.0094029643600097471100311e0L,
0.0554269923329587516840678e0L, 0.0998673524740336752572038e0L,
0.0450752305681049246641588e0L, 0.0630094224964777393174617e0L,
0.1261383225537664703013000e0L, 0.1273864433581028272878710e0L,
0.0857650041431182051421409e0L, 0.0710288484231025339744731e0L,
0.0502638357285794240375983e0L, 0.0046836700106090938104326e0L,
0.1235837891364555000245005e0L, 0.1148933497158144016800200e0L,
0.0125257577422612263339148e0L, 0.1239572396231834242194190e0L,
0.0250130641375031057952595e0L, 0.0491595791814613009425885e0L,
0.0225916737495647471330203e0L, 0.0636276297878272455926934e0L,
0.0995006582734679464319326e0L, 0.0704822000271856536609874e0L,
0.0651229733939833564587270e0L, 0.0399822915031365972479053e0L,
0.0345651225708028750983205e0L, 0.0022121679758841144327603e0L,
0.0814032642594593804596783e0L, 0.0658321344760055290627354e0L,
0.0259291372645079254606423e0L, 0.1187141856692283347609436e0L,
0.0599994760538597198558967e0L, 0.0550093798019804173691026e0L,
0.0052644224217646559697603e0L, 0.0153312687405658695933837e0L,
0.0352715936975012310045570e0L, 0.0500055643165395512421280e0L,
0.0574416483117972010634072e0L, 0.0159882379728381343830125e0L,
0.0263566041022088499347248e0L, 0.0119600393794554109167011e0L
};
long double ldY = 0.0e0L;
long double ldOffset; long double ldMidpoint;
long double ldHalfInterval;
int iKnots;
int i;
iKnots = iLen[iRuleChoice];
ldHalfInterval = ( ldB - ldA ) * 0.5;
ldMidpoint = ldA + ldHalfInterval;
for ( i = 0; i < iKnots; i++ ) {
if ( i >= *pI1 || i >= *pI2 ) {
ldOffset = ldHalfInterval * ldAbscissae[i];
if ( i >= *pI1 )
pldVectorOne[i] = ( *ldF )( ldMidpoint + ldOffset, pldConstArray );
if ( i >= *pI2 )
pldVectorTwo[i] = ( *ldF )( ldMidpoint - ldOffset, pldConstArray );
}
ldY +=(pldVectorOne[i]+pldVectorTwo[i])*ldWeights[iStart[iRuleChoice]+i];
}
ldY *= ldHalfInterval;
if ( *pI1 <= iKnots ) *pI1 = iKnots;
if ( *pI2 <= iKnots ) *pI2 = iKnots;
return ldY;
}
 (xn), and let h be the width of each part, (b-a)/n. Then find polynomials that fit through those points and integrate them to approximate the area under the curve. You can think of higher-order Newton-Cotes rules as integrals of quadratic equations, cubic equations, and so on, that approximate your original function. William Press' Numerical Recipes in C (Cambridge University Press, 1992) shows how to create your own Newton-Cotes formulas.
(xn), and let h be the width of each part, (b-a)/n. Then find polynomials that fit through those points and integrate them to approximate the area under the curve. You can think of higher-order Newton-Cotes rules as integrals of quadratic equations, cubic equations, and so on, that approximate your original function. William Press' Numerical Recipes in C (Cambridge University Press, 1992) shows how to create your own Newton-Cotes formulas.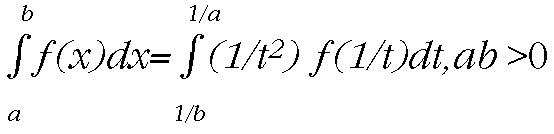{kind=link}