Introduction
Neural networks are a capable technology but they are still poorly understood by many programmers. Neural networks learn how to recognize patterns and solve problems that befuddle other types of computer programs. Coded once, a good neural network program (simulation) can be trained to solve a variety of different problems.
This article reviews some neural network basics from a previous article I wrote for CUJ [1] and demonstrates how to implement backpropagation — a versatile and widely used form of neural network.
Neural Network Basics
Neural Networks existed in concept as far back as the 1960s. One of the elements conceived at that time was the adaptive linear combiner (Figure 1) — the basic building block of all neural networks. The adaptive linear combiner multiplies the inputs (x) by the weights (w) and yields the sum of these products. The C code for an adaptive linear combiner is simple:
ELEMENT x[], w[], result = 0.0 for (i = 0; i < size; i++) result = result + x[i]*w[1];
Figure 2 shows the adaptive linear element or Adaline — the simplest neural network. It consists of an adaptive linear combiner and a signum function (output is -1 for negative input, +1 otherwise). The Adaline feeds back an error to alter the weights. The a-LMS learning law (described in my previous article) allows you to train the Adaline to produce correct answers. My previous article showed how to train the Adaline to solve linearly separable problems such as shown in Figure 3.Figure 4 shows the multiple adaptive linear element or Madaline. The Madaline comprises several Adalines and a final decision maker (the AND, OR, majority box). In [1] I explained how the Madaline could distinguish non-linearly separable patterns like that shown in Figure 5, and showed how the Madaline could recognize a basic handwritten character.
The Adaline and Madaline date back to the early 1960s. Neural networks almost died in the 1970s, but were reborn in the 1980s with the introduction of the backpropagation network.
Backpropagation
Figure 6 shows a backpropagation neural network. The table embedded in the figure refers to source code variables — you can ignore it for now. The network has inputs (x) on the left, outputs (y) on the right, several layers of connected nodes, and a feedback loop (delta). The inputs feed forward through the network of adaptive linear combiners. At each node the sum of the products of inputs and weights goes through a sigmoid function (Figure 7) that compresses the result to between 0 and 1. This compression provides a nonlinear characteristic. It also requires using floating-point operations instead of the integers used in the Adaline and Madaline.
The backpropagation neural network has several layers of nodes, unlike the Adaline, which had only one node, and the Madaline which had one layer of nodes. Multiple layers and more nodes can solve larger, more complex problems.
The backpropagation network also has multiple outputs. The Adaline and Madaline had one output with two states (-1 and +1). Multiple outputs allow multiple output classes. The examples given later demonstrate the power and flexibility of this feature. Multiple outputs also mean multiple targets and deltas for training (explained below). This requires an involved training algorithm.
Training a Network
Before it is used to solve a problem, a neural network undergoes a sequence of steps known as training. Training is an iterative process that adjusts the weights at each node until the network is able to solve a particular kind of problem (e.g. distinguish between several handwritten characters). The training algorithm supplies the network with a sequence of inputs and desired ouput values (targets). The network is trained until it produces the desired outputs from a set of inputs. During training, deltas (targets - outputs) feed backwards through the network to adjust the weights of the combiners. The propagation of errors back through the network gives backpropagation its name.
Propagating Errors Back Through the Network
Backpropagation's weight adjustment (training) process is somewhat involved and difficult to explain. Nevertheless, I'll take a crack at it. The math is a bit confusing, but the final source code is simple. If you are not a math fan, skip to the next section.
The foundation of the process is the sigmoid function and its derivative shown in equations (1) and (2) and in Figure 7. The sigmoid function produces the final output of each neuron. "Almost correct" answers fall near 0 or 1 while answers contributing to error fall in the middle. Adjusting weights is the job of the sigmoid derivative. The derivative is greatest for middle values (those contributing the most error) and small for larger values (almost correct). Therefore, the derivative adjusts the "almost correct" answers by a small amount and incorrect answers by a greater amount.
Equations (3) and (4) show how to calculate the error in the output (y) layer. The delta (d) is the derivative of the output times the target minus the output. Equation (4) is actually equation (3) rewritten to compute one element of a delta vector. Equation (5) shows how to change the weights in the output layer.
Here, wout and d refer to matrices and vectors respectively. 2µ is a constant you can set at compile time (more on this later). Changing the weights in the hidden and input layers follows a similar process. The first step calculates the delta (h delta) for each neuron output (h) in the network using equation (6) . This is a derivative just like that shown in equation (2) . h and w refer to the current layer's neuron output vector and weights matrix respectively. dprev refers to the vector of deltas calculated from the previous layer (that is, the layer closer to the output layer). The second step updates the weights throughout the network by using equation (7) . This process changes all the weights throughout the network during every backward pass. The amount of change is proportional to the "error" that each neuron contributes. The 2µ factor in equations (5) and (7) ensures the network does not correct too much and oscillate.
Using a Neural Network
Like other trainable neural networks, using the backpropagation network requires three steps. The first step is to enter data with known correct answers. Second, train the weights in the network using the backpropagation scheme described above. Third, use the trained network on new data. Entering the data can be tedious and error prone, but using ASCII files for input eases this burden.
A Backpropagation Program
Now let us build a backpropagation neural network program called backprop. Returning to Figure 6, Inow direct your attention to the embedded table I told to you ignore earlier. This table gives the source code variables corresponding to the components of the neural network.
The user provides the scalars m, n, o, and p as input to backprop. Inputting these numbers gives the user the flexibility to specify the size and shape of the network at run time. backprop allocates all the arrays dynamically.
backprop is designed to operate in one of three modes — input, training, and "working" mode. The program runs in the mode it was invoked with, then shuts down. Between runs the program keeps most of its arrays on disk. backprop uses six data files, to store the inputs (x), the outputs (y), the targets, and the weights for the network (win, whid, and wout).
backprop also uses three optional ASCII files. (While these are technically data files as well, I call them ASCII files here to distinguish them from the data files mentioned above.) The ASCII files make the program easier to use by reducing repetitive typing and allowing the user to alter inputs and target values by editing rather than reentering. The ASCII parameters file specifies operational parameters such as input and output file names, number of nodes per layer, and mode of operation. An example is shown as follows:
mode training m 2 n 4 o 3 p 5 data-sets 6 type sigmoid in-file 2input.xxx out-file 2output.xxx target-file 2target.xxx h-file 2h-file.xxx win-file 2winfile.xxx whid-file 2whidfil.xxx wout-file 2woutfil.xxx
The ASCII input file allows the user to type the data inputs (x array) in an ASCII file using an editor instead of keying them into the program every time. The ASCII targets file does the same for the target array.In the input mode, backprop reads the parameters, input data, and targets from ASCII files and saves the input and targets to data files. In the training mode, backprop reads the parameters from an ASCII file and the input and target data from data files. backprop trains the network using the input and target data and then writes the trained weights (win, whid, and wout) to data files. The working mode is the simplest as backprop reads the parameters from an ASCII file and the input data and weights from data files. After processing the input data, backprop writes the output to a data file.
A Look at the Source
What really goes on inside a neural network program? For one thing, lots and lots of looping. Listing 1 shows the code segment for the training mode. This is the complicated mode because training must continue until the program produces the correct answer for every set of training data. First, the program reads the sets of input data and the targets for that data (read_from_file). After initializing the weights in the network, the program moves into a set of while loops that continue until either the network produces correct answers for every data set or the training exceeds a TRAINING_LIMIT.
The functions input_layer, inner_layers, and output_layer calculate the outputs of the input neurons, inner neurons, and output neurons respectively, from the training input data. These same functions are used in working mode. Listing 2 shows function input_layer. x is a one-dimensional input array and win is a 2-D array of weights. (Weights require a 2-D array because every neuron has m weights.) The matrix_multiply function calculates x*win and stores the resulting output (a vector) in tmp. apply_function applies the sigmoid function to each element of the vector tmp. (Making type anything other than "sigmoid" causes the program to terminate.) Deep in its guts, apply_function resolves to
double a, b, c; a = (double)(input_value) b = exp (-1.0*a); c = 1.0/(1.0 + b); result = (ELEMENT)(C);The function copy_1d_to_2d copies the vector tmp to one column of the neuron output matrix, h. (h is 2-D because the network has n layers of p neurons each.)
output_layer_error calculates the delta between the output y and the target, using equation 4. If the delta is small enough, training on that data set ends. If not, neuron_deltas (Listing 3) calculates the errors in all the layers of the network.
change_output_weights, change_hidden_weights, and change_input_weights modify the weights using the equations shown earlier. When training ends, the program writes the trained weights to data files.
Listing 4 shows the code segment for the working mode. In this mode, the program reads the input data for the problem and the trained weights for the network. The program processes this data through the input, hidden, and output layers and writes the answer to disk.
Solving Problems with Neural Nets
The following examples illustrate how the backpropagation neural network can solve different problems. Note that the source code remains the same while the user trains the network for the different problems.
Be careful when training the backpropagation neural network. backprop allows selection of the layers in the network n and the neurons per layer p. Specifying too many layers and neurons causes the weights to memorize the inputs and outputs. Training stops after one iteration, and the network cannot solve problems. Too few layers and neurons cause the network to train forever because it doesn't have the capacity to adjust to all training data sets.
You can change the source code to adjust the TWOMU and MIN_ERROR constants. TWOMU decides the rate at which the weights change. If TWOMU is too large, the weights change too much and training can oscillate. I found TWOMU = 0.7 usually works. The MIN_ERROR constant determines when the output is close enough to the target. I used 0.02 for most cases.
Figure 8 shows a nonlinear problem where the backpropagation neural network must classify two-dimensional inputs into one of three output classes. I used four layers of neurons with five neurons in each layer. I changed the MIN_ERROR constant to 0.04, and the network needed 63 passes through all the data sets to train itself. Notice how the multiple outputs come into play here. The Madaline of [1] could not tackle this problem because it had only one output.
Figure 9 shows an example of using the backpropagation neural network to recognize handwritten numbers. I wrote the numbers 1 through 8 in 5x7 arrays and shaded the squares containing any part of the handwritten characters. The 35 squares are the inputs to the neural network with shaded squares having the value 1 (0 for the white squares). There are eight output classes, and a binary coding can represent these with only three outputs. This shows another advantage of the multiple-output capability of backpropagation neural networks.
In the handwriting case, I used a network with three layers having ten neurons per layer. This worked well enough and trained itself in 108 passes through the data shown. The network also trained itself when I specified 20 neurons per layer (101 passes through the data). After training, the backpropagation neural network recognized similarly scrawled numbers.
Complete Source Code
The complete backprop source is available on this month's code disk and via the online sources listed on page 3.
Reference
[1] Dwayne Phillips. "The Foundation of Neural Networks: The Adaline and Madaline," The C Users Journal, September 1992, pp. 69-92.
Dwayne Phillips works as a computer and electronics engineer with the U.S. Department of Defense. He has a PhD in Electrical and Computer Engineering from Louisiana State University. His interests include computer vision, artificial intelligence, software engineering, and programming languages.
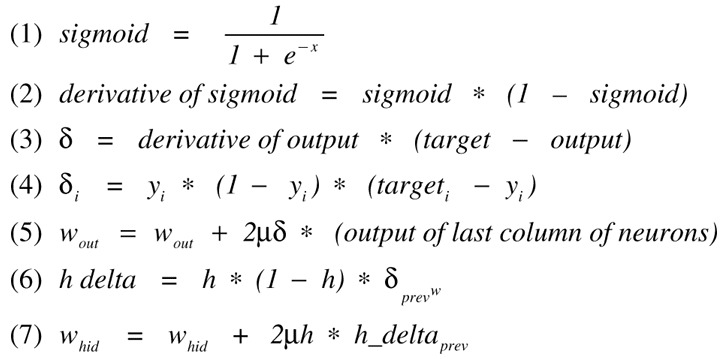{kind=link}