Figure 1: Embedded semantic example.
Dr. Dobb's Digest November 2009
John Hebeler is a division scientist at BBN Technologies. Andrew Perez-Lopez is a Software Engineer at BBN Technologies. They are co-authors of Semantic Web Programming.
Service-Oriented Architecture (SOA) is the de-facto architectural standard for many small and large distributed solutions. Its growing relevance is reflected not only in the bevy of rich services the SOA stack offers, but also the variety of available implementations, many of which are open-source. Yet SOA remains challenged in several areas dealing with scale, growing complexity, diverse knowledge management, and the inherent dynamics of large, distributed systems. These challenges unnecessarily constrain SOA solutions causing them to fall short of their ultimate potential.
Semantics can help. Semantics form expressive, useful computing abstractions or concepts that address these challenges and strengthen the SOA mission to use and leverage complex information and services across an entire enterprise or the globe.
In this article, we examine adding semantics to SOAs through four examples, each contributing in different ways yet adhering to the SOA standards and goals. Two examples illustrate "SOA-ize" semantic services and the other two "Semantic-ize" the SOA. All contribute to improving the scope and capabilities of what is possible with a SOA solution.
SOA exists as a set of standards and services that form a dynamic distributed service fabric that provides a step forward into distributed computing possibilities. The interface standards allow services to interact despite fundamental platform differences. SOA and services is analogous to the World Wide Web (WWW) and documents -- the WWW exists as a set of standards that allow document contributions based on many technologies and techniques all following the same document standards. SOA attempts to do the same with services. Whereas WWW standards unleashed a world of information, SOA attempts to unleash a world of services. However, services can be much more complex and temperamental than documents (and documents themselves have gotten pretty complicated). The SOA stack addresses some of this complexity by integrating a set of management services. The vastness and richness of the network services can easily overwhelm a SOA solution even with a powerful stack of services.
Theoretically, a SOA implementation can exist at a variety of levels from a small solution integrating a handful of services up to a large, dynamic solution integrating thousands of services. In practice, SOA strongly leans to the former -- integrating a few, well-controlled services. Yet the real power and possibilities require a much bigger leap into the thousands. That leap incurs a multitude of challenges including service complexity, information complexity, and service management complexity.
Services are the fundamental building blocks of a SOA solution. Service complexity refers to the degree of sophistication associated with the tasks the service actually accomplishes. Whereas a document is merely a bunch of organized words, services do things -- potentially very complex things. Additionally, they are dynamic. Services are often bound to the objects that drive their behavior. But these objects themselves can limit the ultimate complexity of the overall application. Objects or instances are bound to their creating class and often that class is static. Attributes and relationships are typically also bound to the creating class. Too often in object-oriented software for services, there is little analysis of the object structure as the underlying data model. Is it consistent? Is it logical? Is it cohesive? These answers are left solely to the programmer, and the hard-coded software. Complex behavior frequently yields complex code -- often unreadable code. Some tools exist to help externalize this inherent complexity but most do not. Programming languages can also limit the complexity and thus the power of individual services. SOA solutions integrate multiple services, which, of course, compound this phenomenon.
Information processing is often at the heart of a SOA solution or almost any computer solution -- information is the "crown jewels" of computing. Just as the complexity of services stands as a challenge to SOA system designers, so too does information complexity. Most data technologies incorporate limitations that force the information to reside in multiple places and to be reassembled to produce the desired results. A typical way of addressing this data distribution issue is with XML. Databases, combined with business logic, produce data elements that can form the desired answer in XML. XML is a step in the right direction, but it struggles with complex relationships and dynamic constraints. The actual meaning of the data, the information, is separated in the document and in the XML schema, or even worse, the schema of the database back-end, and therefore very difficult to manage. These limitations of the information format and knowledge representation force all of the services in the enterprise, which should be focused on business logic, to handle a higher degree of complexity just to get started. This, of course, further aggravates the service complexity challenge outlined above.
SOA solutions enable the dynamic integration and collaboration of multiple services. This requires service management -- and this can be very challenging. In a real sense, the integration of services forms new, more complex services. We examine three aspects of service management:
Each represents a major aspect of service management.
Service abstractions describe the services. The richer and more complete the abstractions, the more easily the service is found and properly used. Most SOA services exist as low-level or simple abstractions. This low level forces the programmer to take up the slack and really understand the service beyond the simple abstraction descriptions. For example, say a software developer determines the need for a service, like a catalog lookup. Given a high-level abstraction like "catalog lookup" the developer would, in an ideal SOA world, find a service and be able to integrate it easily into an application at that high level. However, as we in the real world know, to take advantage of the catalog lookup service, a SOA service too often requires inspecting complex APIs defined in Web Service Description Language (WSDL), which identifies particular end point names, the numbers and types of variables, and return values for each supported method. Even those detailed WSDL descriptions, however, do not describe how the parameters serve the method, the purpose of the method, or any expectations with regard to errors and performance. This forces you, the programmer, to invert your development process in an unnatural way. Instead of finding a service that matches the needs of your application, you must design your application to match the requirements of the services. In other words, the services don't really serve your specific need, they serve their own needs in their own particular way. You must call and use the service according to the service's usage patterns and not your own. Of course, all of this is moot if you design all the services, or if all of the assumptions are shared by every service, etc -- but that is extraordinarily limiting in terms of the services that your application can exploit, and is really contrary to the goal of large-scale SOA. The key is inverting this perspective and enabling a service to align with your system's needs. Thus, your SOA system accesses the services or aggregation of services at the level of abstraction that makes sense to your needs. This is somewhat analogous to views for a relational database. This service view must also accommodate similar services, failed services, and so on. Ideally, you just want your overall system to operate correctly and not have to change drastically to accommodate the specific syntax or other dependencies of a particular service implementation.
Service registration remains a real challenge for SOA. How can you compose the best SOA without full knowledge of what services are available and how to interact with them? The Universal Description, Discovery, and Integration (UDDI) standard has fallen short of realizing its larger goals. The inherent complexity of using XML to represent such rich knowledge has produced an unwieldy solution that befuddles many developers. Many SOA solutions now register their services in hand-carved proprietary solutions or use no UDDI implementation at all, and some even try to use a Wiki. This is a direct blow to the scale of SOA efforts. A quick look at programmableweb.com illustrates this problem. This site lists thousands of web services, yet only a handful are used to support almost all the mashups and the vast majority of mashups use only two or fewer services (with a 40% chance that one of these is Google Maps). Sadly, most offered services are not used in any mashups. This situation could be the result of inadequate services but it is more likely due to the inability of developers to find and utilize the services they want.
For SOA to work properly, a service registration system must clearly describe and search a vast array of different service offerings available in the given SOA. These requirements demand a solution that is more than just a common set of syntaxes. Explicit syntax agreements are important, for without them nothing would work. However, determining a common syntax (or set of syntaxes) only allows exact matches or at best a basic category search. This works fine for services that you control (and name) but does not stand up to the challenge of integrating services that originate and evolve from many sources. Actually, for services you create, the registry is not even that important -- you already know the descriptions. However, large-scale integration needs much more than a common syntax -- it needs a common semantics. Capturing the information about what a service is and what it does and communicating that information effectively in an automated way remains a key challenge for large, dynamic SOA implementations.
Service abstractions and registration contain another inherent challenge -- dynamics. Over time, services change -- that is a simple rule, and they usually change for the better. Traditional SOA techniques often create brittle connections to services that may break on the slightest change to the service. Again, this is no trouble if you develop and control the services, but again, that is contrary to SOA's goal. This inhibits the use of services to two types: those that you control or those that are so big they will never (or at least very rarely) change. This set describes only a small fraction of the available services, and requires that SOA applications have regular, and often significant, maintenance. Without better ways to deal with the dynamics of web services, the growth of an SOA solution will remain stunted and more costly.
These SOA struggles result in a reduced awareness of what is available, a limited capacity to compose services, and a diminished exploitation of valuable services due to uncontrolled changes. In an ideal world, SOA could seamlessly link services around the globe, but these factors significantly threaten that vision.
Semantic technologies capture meaning and employ it to ease communication between services. This meaning can be used to give richer descriptions at all levels of the SOA, from the underlying data to individual service descriptions to aggregate service descriptions. Semantic technologies can strengthen the SOA mission by absorbing and leveraging higher levels of complexity at every level. For example, semantic technology can organize data and processing to better reflect a person or a company -- the meaning forms complex, dynamic concepts beyond other methods.
In the case of computers, the use of the term semantics can easily be confused with human understanding, but make no mistake: computers using semantic technologies do not understand anything. Computers simply process information -- but if the information is represented in such a way that it is imbued with more of it's meaning, then computers can act upon that information. For example, a series of statements and data structures in a programming language may capture the approval process of a loan application. In a sense, the programming code captures the meaning behind the approval and denial of a loan. A programmer carved the business meaning directly into code. However, the computer system executing that code has no conception of the higher level task it is accomplishing -- it has no way of representing the idea of a loan application. Likewise a database programmer can design database tables and columns to achieve similar results, thereby encoding the business logic into the data representation. The meaning is in there -- but not well organized or abstracted. The fact remains that it might be theoretically possible to extract the semantics of loan approval from the code and associated databases, but it is not cohesive or easy to identify. You can't easily find, organize, and distinguish the meaning parts from other coding parts, the meaning get tightly coupled with the program logic and database schemata. Where do you go if the loan procedure changes? Is the meaning consistent? When an error occurs, where is the culprit? These questions quickly haunt complex SOA solutions, and result in systems that that tend to scatter meaning and lose their ability to adapt.
Luckily, other technological forms of semantic representation exist that offer a range of expressivity or meaning capture that better serves these challenges. Now you might think the right choice of semantic technology for your applications would be the most expressive and sophisticated one available, such as first order logic or even richer forms. However, oftentimes the more complex a representation is, the more difficult it is to use. The harder a technology is to use, the less widely it is adopted. And less adoption means failure when SOA solutions attempt to span the globe. Large scale SOA is a critical mass solution. What is needed is a flexible approach that balances complex expressivity with ease-of-use participation. Albert Einstein famously said that "Everything should be made as simple as possible, but not simpler." A prominent Semantic Web researcher, Dr. Jim Hendler, was quoted as saying something that could be thought of as a corollary: "A little semantics goes a long way". This level of information representation that is richer than traditional data models but still designed for Web-scale performance is a perfect fit for Semantic Web technologies. The Semantic Web represents meaning as a directed graph of binary relationships between resources. That is, one resource is related to another resource through a directed link called a predicate. A resource can represent anything, and need not be a web page or service. With respect to services, Semantic Web relationships can be thought of as falling into three relationship categories: instance relationships, structure relationships, and constraint relationships.
The last two types of relationships enable tools called reasoners, to infer additional relationships or entailments regarding the provided statements. For example, a reasoner could infer that John is a Living Thing from statements in 2 above and that Mary is a Person from the statements in 1 and 3 above. This is very powerful because we see that the data itself generates additional data -- no human is required.
Several other traits of the Semantic Web are also important to keep in mind. First and foremost is that it is an accepted, open, W3C standard. This protects your investment in a semantic data model while also encouraging wide participation from a community of researchers and professionals to develop tools, methods, and even additional semantically-enabled data sources. Secondly, the Semantic Web is run-time dynamic. Semantic Web solutions can change structure and constraints at any time. This flexibility allows solutions to maintain constant alignment with the changing goals of a SOA solution or service. Lastly, the structure of the Semantic Web is completely independent from the instance data. Thus, structure can evolve independently from the instance data and multiple structures can simultaneously exercise the same instance data. The structure and constraints semantics emanate from the same language constructs as the instance data. There is no difference between information model underlying the three relationship categories. In contrast, relational databases have significant language differences between the structure or database schema and the instances or rows. This feature of Semantic Web systems allows a solution to explore the Semantic Web through structure, constraint, and instance patterns all expressed in the same language.
A collection of these semantic statements containing instances, structure, and constraints offer the ability to create and manage rich, complex semantics. We can apply these semantics directly to the challenges of SOA. Simply put the Semantic Web cohesively forms meaning above and beyond the syntax offered by SOA and helps form a cohesive approach to meaning throughout SOA. So, how does this help?
We now help illustrate those semantic enhancements in four examples. Two examples illustrate SOA-izing your Semantics by adding semantic services to a SOA solution and two illustrate Semantic-izing your SOA through adding semantic capability to fundamental SOA design constructs.
SOA-izing your Semantic Web applications makes them available to the wide, powerful ecosystem established through SOAs. These semantic applications, exposed as standard services allow organizations to bring the benefits of semantics into their enterprise-wide SOA solutions using familiar and compatible SOA interfaces. Consumers of the service need not even be aware that semantic technologies are employed in the implementation of the service. The first example simply embeds the Semantic Web into its service and then communicates with SOA through traditional SOA interfaces. This is certainly not earth-shattering but it is important to point out how this simple integration offers semantic benefits to the SOA world. The second example forms a SPARQL endpoint, an emerging standard, into a standard SOA web service. This opens up a semantic knowledgebase directly to the SOA allowing deep interrogation of the underlying knowledgebase from other semantic services.
The two together help illustrate the value in contributing the power of knowledgebases, reasoners, and dynamic, semantic representations to a SOA. This enables the SOA solution to include semantics at the service level to best accomplish its mission. These examples illustrate techniques to address the challenges of information complexity and service dynamics. The underlying semantics enable rich information expressions and interrogation to meet the challenge of information complexity. The information dynamics inherent to the Semantic Web allow run-time adjustments to the semantic data, its semantic structure and constraints.
Embedded Semantic Web SOA Service
Embedding semantics into a SOA service is straight forward. The service establishes its traditional SOA interface and registration. This exposes, to varying degrees, the value in forming, manipulating, and querying a complex knowledgebase but by maintaining a service layer, the subscribing client need not know anything about the Semantic Web. This provides the benefits of Semantics without adding any complexity to other SOA services.
This example shows two key parts of the embedded semantic service; the service declaration and service implementation that contains the Semantic Web constructs. The latter illustrates the knowledgebase composition. This maintains a complete decoupling between the Semantic Web and the other SOA services.
Our example provides a semantic service that accesses the catalogs of several suppliers. The Semantic Web technologies are ideally suited for such integration. The Semantic Web technologies describe the contents of each vendor's catalog for easy integration. The translation from various data forms to the Semantic Web RDF is often easily done using XSL transformation or some equivalent. RDF, the de-facto language of the Semantic Web, expresses relationships among concepts and allows for the transparent integration of multiple catalogs.
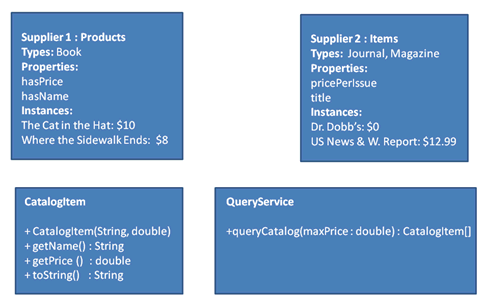
Figure 1 contains two basic catalogs from two suppliers. The first supplier's vocabulary describes Products, of which some are Books. Products names and prices are described using the hasName and hasPrice predicates, respectively. The second supplier describes Items, of which some are Journals and some are Magazines. Their names and prices are similarly described, but with different predicates: title and pricePerIssue. Finally, Figure 1 shows the simple query service and associated business object to represent a catalog item with a given price.
Using just a few lines of the Web Ontology Language (OWL), you can describe the relationships between the concepts from the first supplier's information model and those from the second supplier's.
@prefix owl: <http://www.w3.org/2002/07/owl#> . @prefix one: <http://example.com/supplierOne#> . @prefix two: <http://example.com/supplierTwo#> . one:Product owl:equivalentClass two:Item . one:hasPrice owl:equivalentProperty two:pricePerIssue . one:hasName owl:equivalentProperty two:title.
The two different suppliers use different vocabularies to encode their catalogs, and the fact that supplier two has the notion of a pricePerIssue suggests that there might be some significant differences between their wares. However, for the purposes of a price check into the catalogs, those differences can be ignored, and the classes and properties above can be thought of as equivalent. Then, using just a few lines of Java code, you can combine the three models -- the data from the two suppliers, and those OWL statements that serve to align the data models:
supplierOneModel = loadModel("resources/supplierOne.tur", "TURTLE"); supplierTwoModel = loadModel("resources/supplierTwo.tur", "TURTLE"); jointModel = loadModel("resources/alignment.tur", "TURTLE"); jointModel.add(supplierOneModel); jointModel.add(supplierTwoModel);
After the models have been added to the joint model, a query can be written that exclusively uses the vocabulary of the first supplier which will still return results from the second supplier's catalog. This is because the equivalences defined in the OWL above allow a reasoner to infer that all Items from the second supplier's catalog are equally validly referred to as Products, like those from the first supplier's. When executed against the model, the query returns The Cat in the Hat and Where the Sidewalk Ends, but also Dr. Dobb's, because all three cost less than $12.
PREFIX one: <http://example.com/supplierOne#> SELECT DISTINCT ?name ?price WHERE { [] a one:Product ; one:hasName ?name ; one:hasPrice ?price FILTER(?price < 12.00) . }
SPARQL Endpoint SOA Service
Rather than use semantic technologies behind the scenes as with the first example, a service could alternatively choose to expose them to other semantic-enabled services. This allows SOA services to work together to form a solution while taking advantage of the semantics.
The Semantic Web community has been interested in the complementary role that semantic technologies can play in SOA systems for some time. The World Wide Web Consortium (W3C)-recommended query language for RDF is called SPARQL, and the community is working towards standard artifacts for easy communication with SPARQL endpoints.
The next example illustrates how easy it is to expose semantic data as a SPARQL endpoint. We modify the previous example to accept arbitrary SPARQL SELECT queries and return the results according to the XML ResultSet schema that the SPARQL protocol uses. Assuming the same scenario as in the first example, exposing the combined catalogs as a SPARQL endpoint can give more visibility into the data by clients that are aware of semantic technologies. Here's an excerpt from the implementation the service class:
@WebService public class SPARQL { private final Object _lock = new Object(); private final ResultSetFormatter _resultSetFormatter = new ResultSetFormatter(); private boolean _initialized = false; private Model _model = null; private final String SUPPLIER_ONE_FILE = "resources/supplierOne.tur"; private final String SUPPLIER_TWO_FILE = "resources/supplierTwo.tur"; private final String SUPPLIER_ALIGNMENT_FILE = "resources/alignment.tur"; private Model loadModel(String fileName, String format) { // model loading code, removed only because it is // very similar to the code shown from the first example... } private void loadModel() { _model = loadModel(SUPPLIER_ALIGNMENT_FILE, "TURTLE"); _model.add(loadModel(SUPPLIER_ONE_FILE, "TURTLE")); _model.add(loadModel(SUPPLIER_TWO_FILE, "TURTLE")); } private void initialize() { if(!_initialized) { synchronized(_lock) { if(!_initialized) { loadModel(); _initialized = true; } } } } public String query(String query) { initialize(); String toReturn; QueryExecution qe = QueryExecutionFactory.create( query, _model); ResultSet results = qe.execSelect(); toReturn = _resultSetFormatter.asXMLString(results); return toReturn; } }
The SPARQL protocol specification defines an XML result set format which is returned by this code. This example depends on the Jena Semantic Web Framework, an open source implementation of many of the Semantic Web technologies that has come to be very popular in the Semantic Web community. One of Jena's components is ARQ, an implementation of the SPARQL query language, and ARQ provides the classes for executing queries and for serializing their results into the XML result set format. Below is the WSDL generated for this query service:
<?xml version="1.0" encoding="UTF-8"?> <definitions name='SPARQLService' targetNamespace='http://service.example2.ssoa.ddj.com/' xmlns='http://schemas.xmlsoap.org/wsdl/' xmlns:soap='http://schemas.xmlsoap.org/wsdl/soap/' xmlns:tns='http://service.example2.ssoa.ddj.com/' xmlns:xsd='http://www.w3.org/2001/XMLSchema'> <types> <xs:schema targetNamespace='http://service.example2.ssoa.ddj.com/' version='1.0' xmlns:tns='http://service.example2.ssoa.ddj.com/' xmlns:xs='http://www.w3.org/2001/XMLSchema'> <xs:element name='query' type='tns:query'/> <xs:element name='queryResponse' type='tns:queryResponse'/> <xs:complexType name='query'> <xs:sequence> <xs:element minOccurs='0' name='arg0' type='xs:string'/> </xs:sequence> </xs:complexType> <xs:complexType name='queryResponse'> <xs:sequence> <xs:element minOccurs='0' name='return' type='xs:string'/> </xs:sequence> </xs:complexType> </xs:schema> </types> <message name='SPARQL_query'> <part element='tns:query' name='query'/> </message> <message name='SPARQL_queryResponse'> <part element='tns:queryResponse' name='queryResponse'/> </message> <portType name='SPARQL'> <operation name='query' parameterOrder='query'> <input message='tns:SPARQL_query'/> <output message='tns:SPARQL_queryResponse'/> </operation> </portType> <binding name='SPARQLBinding' type='tns:SPARQL'> <soap:binding style='document' transport='http://schemas.xmlsoap.org/soap/http'/> <operation name='query'> <soap:operation soapAction=''/> <input> <soap:body use='literal'/> </input> <output> <soap:body use='literal'/> </output> </operation> </binding> <service name='SPARQLService'> <port binding='tns:SPARQLBinding' name='SPARQLPort'> <soap:address location='REPLACE_WITH_ACTUAL_URL'/> </port> </service> </definitions>
Being able to expose new, richer descriptions of data and the inferences that can be produces from them via standard service protocols is a big advantage, and helps to show SOA solutions can be enhanced with a little semantic technology.
Whereas SOA-izing your semantics brings semantically enriched services to the SOA, semantic-izing your SOA improves the fundamental infrastructure capabilities of SOA. This assists the overall management and composition of the SOA itself. We examine two such additions -- a semantic faade that decouples normal SOA services from a larger, more complex and dynamic SOA service, and a semantic registry that improves on the syntax-oriented offerings by UDDI or other types of implementations.
Semantic Faade SOA Service
A semantic faade offers a method to build robust, complex abstractions from groupings of regular SOA services. The facade might be used to provide high availability by intelligently switching between similar services, align multiple, similar services, or to build complex sequences of services. The semantic faade is made possible by the use of semantic technologies and the inferencing provided by a knowledgebase and associated reasoners. A semantic faade can be used to encode and effect the more efficient use of existing services based on the semantics contained in the faade layer. The capability to semantically unite services aides in managing complexity on all three fronts: service complexity, information complexity, and service management complexity:
Figure 2 contains the standard Faade pattern.
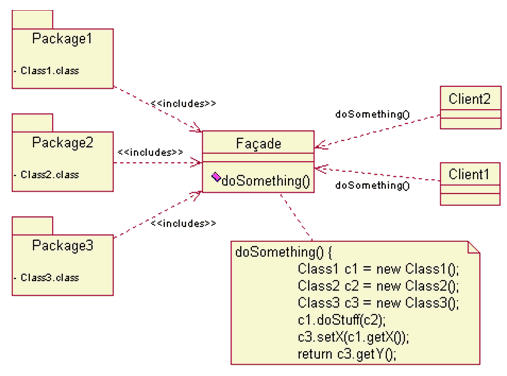
Now the Semantic faade adds a SOA interface layer to interact with both the client and the services (here listed as Package 1 through 3). The doSomething method enables the incorporation of semantics to manage the interactions between client and the services. Figure 3 displays the logical architecture of the Semantic Facade.
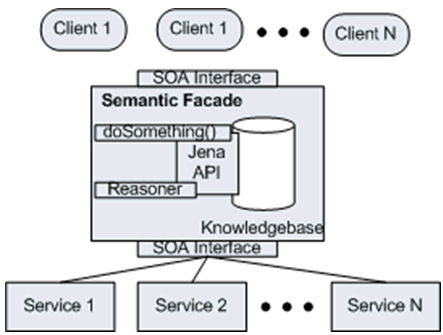
The Semantic faade brings the power of semantics to orchestrate complex service aggregations.
Semantic Registry SOA Service
Existing registries, and their shortcomings, are the Achilles' heel of today's SOAs. No awareness equals no use, and current implementations of service registries make it all too easy for services to fall through the cracks into oblivion. Of course awareness of services from back channels external to SOA can be used on a one-off basis, but this is not a sustainable solution for building a large, dynamic SOA-based application.
Awareness exists on several levels; syntax, functionality, dependencies, assumptions, and sequences. Syntax awareness provides the technical details to exchange information. Functionality awareness provides the purpose of the exchange. Dependencies and assumptions provide the background to exercise the service successfully. Finally sequence awareness provides the logical steps of multiple processes to achieve a larger goal. UDDI and similar SOA services 9 (even LDAP) provide only basic awareness -- allowing insight into syntax, some keywords that describe functionality possibly linked to a taxonomy, and some ancillary information. This is critical information but clearly they would benefit from some additional, rich knowledge about the service and its relationships to information and other services. Semantics can go beyond a taxonomy to find similar services and partnering services. Semantics can maintain alignment to the services as they evolve. Additionally, the complexity of UDDI has limited its implementation and adoption. Semantics can help in managing the complexity of UDDI while also providing a richer description of the service.
Rich semantics would even allow negotiation of services and advance composition. Areas that would enable the self-formation of a service sequence to serve higher level abstractions. This requires advanced, complex service descriptions in addition to the logic to interface properly.
Awareness can be inherent to SOA, where the SOA itself is aware of services. This awareness can improve management for the SOA services. In this case, SOAs can identify busy and non-busy services, leading to better optimization and improved resource utilization. A semantic registry could also provide governance -- a key enabler of advanced, large-scale SOA implementations. A Semantic Registry need not replace any existing syntax-based registry but rather enrich and strengthen the existing registry through semantics. Several potential semantic standards exist. See OWL-S or SAWSDL to see these standardization attempts at adding semantic information to SOA services.
The Semantic Web offers a bridge to the larger goals possible for a SOA and the many available networked services. It provides the conceptual abstractions necessary to collapse the various technologies into more useful computing artifacts and concepts. Additionally, it provides software the dynamism to keep pace with changes inherent to large scale computing especially when using decentralized, heterogeneous SOA components.
The flexibility of the Semantic Web can help to move SOA from relatively small, single-enterprise efforts to massive Web-scale systems that leverage both the services and information available through the Internet. It also provides a powerful set of tools for communicating and manipulating application data, structure and constraints, to align with many different perspectives.
We outlined four examples to illustrate methods where semantic gracefully strengthens SOA. The first two focused on the ease to add semantic capabilities to the SOA service portfolio. The remaining two demonstrated ways to improve SOA itself through improved composition and registration. These examples illustrate ways to better manage complexity at the service, information, and management levels. This complexity management expands the scope and reach of a SOA solution. Using a richer representation for data and service descriptions can empower higher levels of the SOA stack to effectively tackle the ever larger and more complex challenges that the future will inevitably bring.