Peter is a professor of computer science at the University of Southern California. He can be reached at danzig@usc.edu. The software system described here is the result of a collaboration between Anawat Chankhunthod, Chuck Neerdaels, and Peter Danzig of USC, and Michael Schwartz and Duane Wessels of the University of Colorado-Boulder.
As traffic on the Internet continues to grow and new kinds of information (such as audio and video data) are transmitted across it, some of the design limitations behind popular Internet applications become increasingly apparent. If you've recently tried to reach a popular Web site such as Lycos or Yahoo, for instance, you've perhaps encountered delays. Likewise, if your Internet provider has added lots of new users lately, you've likely found the system unusably slow at peak times during the day.
Although some of these problems are strictly local, others result from nonlocal design limitations. Internet information services such as FTP, Gopher, and the World Wide Web have evolved so rapidly that their designers and implementors postponed performance and scalability in favor of functionality and easy deployment. These popular services have been designed with little regard for efficient use of network bandwidth. As an example, they lack caching support in their core protocols.
There are a variety of approaches for addressing Net-related performance problems. The Harvest cache, for example, is a hierarchical object cache designed to make Internet information systems scale better. It has been in use for two years at about 100 sites on the Net and it can function both as a proxy-cache and as an httpd accelerator. As an httpd accelerator, the cache works in conjunction with existing HTTP daemons (Web server software) to increase throughput dramatically. This can be accomplished in a mostly transparent manner.
In this article, I'll present measurements that show that the Harvest cache achieves an order-of-magnitude performance improvement over other proxy caches, such as the cache used in the CERN 3.0 server software. Our results demonstrate that HTTP is not an inherently slow protocol, but rather that many popular implementations have ignored the sage advice to make the common case fast.
The Harvest cache is designed to support a highly concurrent stream of requests with minimal queueing for operating-system-level resources. This is achieved by use of implementation techniques such as nonblocking I/O, application-level threading, and virtual memory management.
The Harvest cache runs under several operating systems, including SunOS, Solaris, DEC OSF/1, HP/UX, SGI, Linux, and IBM AIX. Binary and source distributions for the cache are available from http://excalibur.usc.edu. General information about the Harvest system, including the user's manual, is available from http://harvest.cs.colorado.edu. A commercial version should be available at press time.
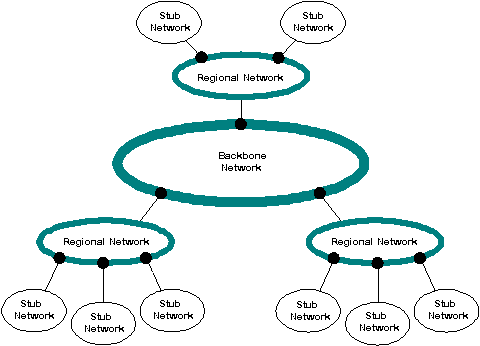
Hierarchical caching distributes server load away from server hot spots raised by globally popular information objects, reduces access latency, and protects the network from erroneous clients. High performance is particularly important for higher levels in the cache hierarchy, which may experience heavy service-request rates. The Harvest cache allows individual caches to be interconnected hierarchically in a way that mirrors the topology of an internetwork, resulting in additional efficiency increases.
In a hierarchical cache, misses at one level are passed to caches located at higher levels, as illustrated in Figure 1. In addition to the parent-child relationships, the cache supports a notion of "siblings" (that is, caches at the same level in the hierarchy) provided to distribute cache server load. Each cache in the hierarchy independently decides whether to fetch the reference from the object's home site or from its parent or sibling caches, using a simple resolution protocol that works as follows.
If the URL contains any of a configurable list of substrings, then the object is fetched directly from the object's home, rather than through the cache hierarchy. This feature is used to force the cache to resolve noncacheable ("cgi-bin") URLs and local URLs directly from the object's home. Similarly, if the domain name of a URL matches a configurable list of substrings, then the object is resolved through the particular parent bound to that domain. Otherwise, when a cache receives a request for a URL that misses, it performs a remote procedure call (RPC) to all of its siblings and parents, appropriate for the particular URL checking if the URL hits any sibling or parent. The cache retrieves the object from the site with the lowest-measured latency.
Additionally, a cache option can be enabled that tricks the referenced URL's home site into implementing the resolution protocol. When this option is enabled, the cache sends a "Hit" message to the UDP echo port of the object's home machine. When the object's home echoes this message, the cache treats it like a hit generated by a remote cache that had the object. This option allows the cache to retrieve the object from the home site if it happens to be closer than any of the sibling or parent caches.
A cache resolves a reference through the first sibling, parent, or home site to return a UDP "Hit" packet, or through the first parent to return a UDP "Miss" message if all caches miss and the home's UDP "Hit" packet fails to arrive within two seconds. However, the cache will not wait for a home machine to time out; it will begin transmitting as soon as all of the parent and sibling caches have responded. The resolution protocol's goal is for a cache to resolve an object through the source (cache or home) that can provide it most efficiently. This protocol is really a heuristic, as fast response to a ping indicates low latency. We plan to evolve to a metric that combines both response and available bandwidth. Hierarchies as deep as three caches add little noticeable access latency. The only case where the cache adds noticeable latency is when one of its parents fails, but the child cache has not yet detected it. In this case, references to this object are delayed by two seconds, which is the length of the parent-to-child-cache timeout. As the hierarchy deepens, the root caches become responsible for more clients. To keep root cache servers from becoming overloaded, we recommend that the hierarchy terminate at the first place in the regional or backbone network where bandwidth is plentiful.
Our trace-driven simulation study of Internet traffic in 1993 showed that hierarchical caching of FTP files could eliminate half of all file transfers over the Internet's WAN links. Other studies seem to arrive at different conclusions. For example, both "Long-term Caching Strategies for Very Large Distributed File Systems," by Rafael Alonso and Matthew Blaze (Proceedings of the USENIX Summer Conference, June 1991), and "Multi-level Caching in Distributed File Systems, Or Your Cache Ain't Nuthin' but Trash," by D. Muntz and P. Honeyman (Proceedings of the USENIX Winter Conference, January 1992), show that hierarchical caches can, at best, achieve 20 percent hit rates and cut server workload in half. We believe the different conclusions reached by these studies is a result of examining different kinds of workloads. Our study traced wide-area FTP traffic from a switch near the NSFNET backbone. In contrast, the other studies analyzed LAN workstation file-system traffic. Because LAN files rarely change over, say, a five-day period, the other studies found little value in hierarchical caching over flat-file caches at each workstation.
In contrast to workstation file systems, applications such as FTP, WWW, and Gopher facilitate read-only sharing of autonomously owned and rapidly evolving object spaces. We found that over half of NSFNET FTP traffic is due to sharing of read-only objects, and since Internet topology tends to be organized hierarchically, that hierarchical caching can yield a 50 percent hit rate and can reduce server load dramatically. Claffy and Braun reported similar statistics for Web traffic, which has displaced FTP traffic as the largest component of Internet packets.
As an httpd accelerator, the Harvest cache pretends to be a site's primary HTTP server (running on well-known port 80). This faux server forwards references that are not present in the cache to the site's real HTTP server, which is attached to port 81. References to cacheable objects such as HTML pages and GIF images are served by the Harvest cache; references to noncacheable objects, such as queries and cgi-bin programs, are served by the true httpd daemon on port 81. If a site's workload is biased toward cacheable objects, this configuration can dramatically reduce the site's Web workload. This configuration is easily deployed and does not require major changes to existing software or document contents.
While the benefit of running an httpd accelerator depends on a site's specific workload of cacheable versus noncacheable objects, the httpd accelerator cannot degrade a site's performance. Further note that objects that don't appear to be cacheable at first glance can be cached with some slight loss of transparency. For example, if a site is providing stock quotes or sports scores, and the workload becomes overwhelming, one can decide to have these objects cached also (this assumes that your user population accepts information being out-of-date by 30 seconds or so).
The Harvest cache supports three access protocols: encapsulating, connectionless, and proxy-http. The encapsulating protocol encapsulates cache-to-cache data exchanges to permit end-to-end error detection via checksums, and eventually, digital signatures. This protocol also enables a parent cache to transmit an object's remaining time-to-live (TTL) value to the child cache. The cache uses the UDP-based connectionless protocol to implement the parent-child resolution protocol. This protocol also permits caches to exchange small objects without establishing a TCP connection, for efficiency.
While the encapsulating and connectionless protocols both support end-to-end reliability, the proxy-http protocol is supported by most Web browsers. In that arrangement, clients request objects via one of the standard information-access protocols (FTP, Gopher, or HTTP) from a cache process. (The term "proxy" arose because the mechanism was primarily designed to allow clients to interact with the Web from behind a firewall gateway.) To reduce the costs of repeated failures (for example, from erroneously looping clients) we implemented two forms of "negative caching." First, when a DNS lookup failure occurs, we cache the negative result for five minutes (chosen because transient Internet conditions are typically resolved within that time frame). Second, when an object-retrieval failure occurs, we cache the negative result for a parameterized period of time, with a default of five minutes.
For efficiency and portability across UNIX-like platforms, the cache implements its own nonblocking disk and network I/O abstractions directly atop a BSD select() loop. The cache avoids forking except for misses to FTP URLs; we retrieve FTP URLs via an external process because the complexity of the protocol makes it difficult to fit into our select() loop state machine. The cache implements its own DNS cache, and when the DNS cache misses, the cache performs nonblocking DNS lookups, although without currently respecting DNS time-to-live (TTL) values. As the referenced bytes pour into the cache, they are simultaneously forwarded to all sites that referenced the same object and written to disk, using nonblocking I/O. The only way the cache will stall is if it takes a virtual-memory page fault; the cache avoids page faults by managing the size of its VM image. The cache employs non-preemptive, run-to-completion scheduling internally, so it has no need for file- or data-structure locking. However, to its clients, it appears multithreaded.
The cache keeps all metadata for cached objects (URL, TTL, reference counts, disk file reference, and various flags) in virtual memory. The amount of memory required per entry is 48 bytes (on machines with 32-bit word size), plus the length in bytes of the URL string. The cache will also keep exceptionally hot objects loaded in virtual memory if this option is enabled. However, when the quantity of VM dedicated to hot-object storage exceeds a parameterized high-water mark, the cache discards hot objects by LRU until VM usage hits the low-water mark. Note that these objects still reside on disk; only their VM image is reclaimed. The hot-object VM cache is particularly useful when the Harvest cache is deployed as an httpd accelerator.
The Harvest cache is write-through rather than write-back; even objects in the hot-object VM cache appear on disk. We considered memory mapping the files that represent objects, but could not apply this technique because it would lead to page-faults. Instead, objects are brought into cache via nonblocking I/O, despite the extra copies.
Objects in the cache are referenced via a hash table keyed by URL. Cacheable objects remain cached until their cache-assigned TTL expires and they are evicted by the cache replacement policy, or the user manually evicts them by clicking the browser's Reload button. If a reference touches an expired Web object, the cache refreshes the object's TTL with an HTTP "get-if-modified."
The cache keeps the URL and per-object data structures in virtual memory but stores the object itself on disk. We made this decision on the grounds that memory should buy performance in a server-bottlenecked system: The metadata for one million objects will consume 60 to 80 MBs of real memory. If a site cannot afford the memory, then it should use a cache optimized for memory space rather than performance.
We evaluated performance in two ways: comparing the cache against the CERN proxy-http cache, and measuring the performance gain achieved by the Harvest cache when used as an httpd accelerator with the Netscape Netsite, NCSA 1.4, and CERN 3.0 Web servers. These measurements were taken on Sparc 20 model 61 and Sparc 10 model 30 workstations.
Our figures show that the Harvest cache is an order of magnitude faster than the CERN cache on hits, and on average, about twice as fast on misses. For misses, there is less difference because the response time is dominated by retrieval costs across the WAN. For hits, our figures show that 60 percent of the time the CERN cache returns a hit in under 500 milliseconds (ms), while 95 percent of the time the Harvest cache returns an object in under 100 ms. The median response time for hits is 20 ms for Harvest versus 280 ms for CERN. The average response time is 27 ms for Harvest, versus 840 ms for CERN. Note that in the cumulative distribution of response times, the CERN response-time tail extends out to several seconds, so its average is three times its median.
When used as an httpd accelerator, the Harvest cache serves documents that are present in the cache with a median response time of 20 ms. By comparison, the medians for hits with Netscape's Netsite and NCSA's 1.4 httpd are each about 300 ms. In the case of a miss, the Harvest cache adds only about 20 ms to the response times of the companion Web servers running on port 81.
We attribute the Harvest cache's high performance to our disk directory structure, our decision to place metadata in virtual memory, and our threaded design.
The Internet's autonomy and scale present difficult challenges to the way we design and build system software. Once a piece of software becomes accepted as a de facto standard, both its merits and its deficiencies may live forever. For this reason, the real-world complexities of the Internet make us face difficult design decisions. The maze of protocols, independent software implementations, and well-known bugs that comprise the Internet's upper layers frequently force tradeoffs between design cleanliness and operational transparency. In building and using the Harvest cache, we faced these tradeoffs. In running the cache over time, we also encountered more subtle problems, such as the interaction between the DNS and our negative cache. These issues go beyond the scope of this article and are discussed in the research report available at http://catarina.usc.edu/danzig/cache.ps.
Alonso, Rafael and Matthew Blaze. "Long-term Caching Strategies for Very Large Distributed File Systems," Proceedings of the USENIX Summer Conference, June 1991.
Danzig, Peter, Michael Schwartz, and Richard Hall. "A Case for Caching File Objects Inside Internetworks," ACM SIGCOMM '93, September 1993.
Muntz, D. and P. Honeyman. "Multi-level Caching in Distributed File Systems Or: Your Cache Ain't Nuthin' but Trash," Proceedings of the USENIX Winter Conference, January 1992.
{kind=link}