ALGORITHM ALLEY
Micha Hofri
Micha, who is the author of Probabilistic Analysis of Algorithms (Springer-Verlag, 1987), can be contacted at hofri@cs.rice.edu.
Introduction
by Bruce Schneier
Anyone can open a book and find an algorithm that sorts an array of numbers. It's much harder to choose--or invent--the sorting algorithm that works best for a particular job. It's about noticing the strengths and weaknesses of different algorithms that do the same thing, and figuring out which set of characteristics most closely matches the needs of the situation at hand.
You can see this distinction in many off-the-shelf software products. The behemoths that most large application-software products have become take up tens of megabytes of memory and are sluggish on all but the fastest of computers. Like sledgehammers, they do the job--effectively, but without flourish.
More interesting are applications on the cutting edge of computing. Missile-guidance systems, where shaving a few clock cycles off the running time of an algorithm can mean the difference between success and failure. Smart cards, where complex applications are crammed into a credit-card device with processors eight bits wide and total RAM measuring in hundreds--not millions--of bytes.
In this month's column, Micha Hofri looks at the analysis of algorithms--specifically, at time/memory trade-offs. With this technique, a programmer can throw extra memory at a problem in order to improve performance, or sacrifice performance in order to decrease memory requirements.
Algorithms can be analyzed with qualitative and quantitative objectives. "Qualitative analysis" answers questions about correctness, termination, freedom from deadlock, and predictability. These questions occasionally need quantitative calculations as well, but we reserve the latter adjective for analysis that concerns performance, which is what this article is all about.
Since the algorithms we look at are performed in digital computers, the two resources of importance are time and space. "Time" is the run time to completion, and "space," the storage area required to hold code and data. Both are always needed, but in most cases, the analysis of only one type of resource is of practical interest. Sometimes the designer can trade off the two to some extent.
Analysts do not use seconds to express results about run time; it is too implementation and platform dependent. Sometimes we count machine instructions, but this, too, is rarely a good idea. It is better to count "roughly similar" source instructions or just the main, dominating, characterizing operations. For example, when analyzing sorting algorithms performed completely in main memory, we could concentrate on counting comparisons that are needed; we could then claim that some part of the rest is proportional to this count, and that whatever remains is negligible. For higher precision, we could count exchanges as well. However, if the sort required frequent disk accesses, we would count only those operations that take much longer to complete. Except in particularly simple situations, there is art to this science.
Space requirements are normally simpler. The area needed for code is rarely interesting for two reasons: It is usually not controllable and, when space is an issue, it is far smaller than the demands of temporary storage for data. An algorithm may have some natural space unit to use: a record, word, node, or fixed-size vector. Otherwise, we simply count bytes.
The analysis we consider skirts issues of platform, language, and compiler dependence. The results have wider validity and do not date as fast. In other words, we analyze algorithms, not programs. An important benefit is that this approach simplifies the needed mathematical models of the algorithms, and eventually, the analysis of those models. The analysis itself is mathematical, and the kinds of mathematics are determined by the model--typically, they include some algebra and combinatorics. Generating functions are often helpful as well. If we want asymptotic results, this immediately raises the ante: We need to use functions of complex variables. Due to space limitations, in this article I'll stick to "back-of-envelope" calculations.
When you need to select a machine or a compiler, the dependencies we shunned earlier are the center of interest. This is a different ball game: Except for statistics, mathematics is rarely any help; the key words here are "measurement" and "benchmarking."
Somewhere in between is simulation. In the present context, it is used as a substitute for mathematical analysis, when the going gets too rough, when our model gives rise to an equation we cannot solve, for example, or when we cannot write meaningful equations. (The latter might be an indication that we do not yet have a good grip on the underlying problem.)
"Mode" refers to the kind of answer the analysis provides. Let us restrict attention for the moment to running time, an issue that arises when an algorithm needs different times to process different inputs (of similar size). This is not always the case: Most algorithms to invert a matrix, run for essentially the same time for all matrices of a given size. This is typical when the algorithm only computes. Algorithms that search for a solution, rather than calculating it, show huge variations.
If the answer of the analysis has to be a bound, then the analyst must find a function f(n) with the following property: To process n items, algorithm A will never use more than f(n) instructions, iterations, or other relevant unit. This is sometimes a desirable assurance, and this is what worst-case analysis provides. The designer of a real-time system may need it in order to prove that his design is within specs.
Such guarantees are reassuring, but not always practical. Consider an example where an algorithm has 4n possible inputs of size n. A bound of 34n operations is not only frightening, it is also nearly meaningless when it is reached in a few--or even n--problem instances only, or even in 10n of the 4n possible inputs. One reason is that even with these large run times, the average time on all 4n possible instances could be far more modest; 2n+7, for example. Second, if n exceeds 30 or so, the probability of hitting one of the unlucky instances is infinitely smaller than that of the machine being shredded by a meteorite. The immensely popular simplex algorithm for linear optimization has exactly such a skewed profile.
Averages are especially important when we consider algorithms that are used repeatedly, such as those that compute trigonometric functions or perform joins over a relational database. These algorithms require an estimate of both the average resource requirements and the likely deviations. This calls for probabilistic analysis that provides the expected run time and its variance (because of the need for the variance to estimate the probable deviations, I shy away from the term "average-case analysis").
The issue just raised is important in the following scenario: You need to choose between two algorithms. Should you choose on the basis of worst-case or average behavior? Often, if one algorithm is better in one mode, it is also better in the other. But in any number of situations, the ordering according to the two modes is reversed. So the answer depends on the more pressing criteria of performance: guarantee versus overall efficiency.
Naturally, there is an in-between mode. It is meaningful for algorithms that live a long time, such as those that maintain data structures, route messages in a network, or supervise a disk channel. Such algorithms may use foresight to advantage and periodically restructure the data or collect statistics to recompute optimal parameters. Then it may be more meaningful to consider the average cost of an operation in a sequence of operations, where such computational "investments" are prorated on the entire sequence, than to look at an isolated operation. The term "amortized analysis" describes such analysis done in the worst-case behavior mode. Because those "investments" can be controlled by user-supplied parameters, this approach is equally meaningful when considering average behavior.
A trade-off is possible if you can save on one resource by spending more on a less critical one. Consider computing a trigonometric function. This is normally done by evaluating the ratio of two polynomials of moderate degree (depending on the desired precision). We could drastically reduce the required time by keeping in storage a table with a few hundred values (or thousands--again, this is determined by the required precision) and using low-level interpolation to derive the desired result. With a very large table we might even skip the interpolation, saving 90 percent or so of the needed time.
A related but different situation arises when computing one value of the function is relatively slow, compared with constructing a complete table. Computing the binomial coefficient BC(n,k) for 0<k n/2 needs 3k additions/multiplications. Constructing a table of all such coefficients for 0knN requires approximately N2+N additions using the standard recursion. If we expect an algorithm to use at least some portion of the table (a common situation), we can save a lot of time by preparing it during the initialization phase.
n/2 needs 3k additions/multiplications. Constructing a table of all such coefficients for 0knN requires approximately N2+N additions using the standard recursion. If we expect an algorithm to use at least some portion of the table (a common situation), we can save a lot of time by preparing it during the initialization phase.
In contrast to these examples, which choose between two methods, there are situations where the trade-off can be parameterized. Here is a simple example: We need to sort a large file on disk. The file is too large to be accommodated in the main memory available for this application. (For now, forget about virtual storage, even if it's technically possible; using it here effectively calls for virtuoso programming and a good deal of a priori information about the original order of the file.) A naive mergesort algorithm reads chunks of the file into storage, sorts each chunk internally, and writes it as a separate file on disk (which we assume has enough free space). Then the chunks are read in parallel and merged into one fully sorted file. Word is the sorting unit, and the file has N words. Let the size of a chunk be n, so that k=N/n chunks are created. Strictly speaking, we would have 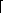 N/n
N/n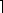 chunks, but to keep it simple we'll assume that N/n is an integer. Let's also assume that with buffers and caches, other tasks running in parallel and sufficient disk bandwidth, the bottleneck is the CPU. We want to optimize the use of this resource.
chunks, but to keep it simple we'll assume that N/n is an integer. Let's also assume that with buffers and caches, other tasks running in parallel and sufficient disk bandwidth, the bottleneck is the CPU. We want to optimize the use of this resource.
The "time" needed to sort n words is An*ln(n) comparisons. A is a constant that we assume known and that depends on the selected algorithm. Several algorithms for internal sort reach this optimal goal (optimal for comparison-based sort, on information-theoretic grounds) on the average, and some variants approach it even in the worst case--with larger constants, but still quite reasonably. The time to merge k streams of size n each is Bk(k-1)n, where B is another constant we assume known (because when we sort in increasing order, k-1 comparisons are needed to determine the smallest word out of the k currently at the heads of the k chunks, and this must be done for all the N=nk words).
The total time is T=Akn ln(n)+Bk(k-1)n=N(A ln(n)+B(k-1)). The storage used is essentially the one buffer of size n. How large should it be? T is minimized when k=1, and as we increase it, the needed storage goes down, and the run time goes up. Where we stop depends on the available physical storage and the demands of concurrent operations. If this sort is needed often enough and the sorting time we get with the current storage limitation is unacceptable, the designer may consider purchasing main memory, and the saved time will be expressed in dollars and cents.
A still-different space/time trade-off appears in the suggestion made by Tom Swan ("Algorithm Alley," DDJ, April 1994) to replace binary search (trees) by search tries with higher fan-out degree. In fact, several variations on the theme expose a variety of trade-offs. The simplest one arises from using more space for internal nodes to represent successive characters in the key, yielding a large reduction in search time.
By far, the richest source for a variety of algorithms and their analyses is still Donald Knuth's The Art of Computer Programming (Addison-Wesley, 1981).
Two additional good sources for algorithms are Algorithmics: Theory and Practice, by Gilles Brassard and Paul Bratley (Prentice-Hall, 1988), and Introduction to Algorithms, by Thomas H. Cormen, Charles E. Leiserson, and Ronald L. Rivest (MIT Press and McGraw-Hill, 1990). The analyses in these books are less ambitious, and usually bounds are considered. The second book gives examples of amortized analysis, as well.
Finally, my book, Probabilistic Analysis of Algorithms (Springer-Verlag, 1987), is mathematical and intended to supply the tools for analysis. However, it is not an "algorithms book." A new, more comprehensive version is due later this year from Oxford University Press.
Copyright © 1995, Dr. Dobb's Journal