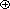 Wt-14Wt-8Wt-3
Wt-14Wt-8Wt-3
William is an independent consultant and president of Comp-Comm Consulting of Brewster, MA. This article is based on material in his forthcoming book, Network and Internetwork Security (Macmillan, due June 1994). He can be reached at stallings@acm.org.
An essential element of most authentication and digital-signature schemes is a hash algorithm. A hash function accepts a variable-size message M as input and produces a fixed-size tag H(M), sometimes called a "message digest," as output (see "One-Way Hash Functions," by Bruce Schneier, DDJ, September 1991). Typically, a hash code is generated for a message, encrypted, and sent with the message. The receiver computes a new hash code for the incoming message, decrypts the hash code that accompanies the message, and compares them. If the message has been altered in transit, there will be a mismatch.
The Secure Hash Algorithm (SHA) was developed by the National Institute of Standards and Technology (NIST) and published as a federal information-processing standard (FIPS PUB 180) in 1993. SHA is based on the MD4 algorithm, developed by Ron Rivest of MIT, and its design closely models MD4. SHA is used as part of the new Digital Signature Standard from NIST, but it can be used in any security application that requires a hash code.
SHA takes as input a message with a maximum length of less than 264 bits and produces as output a 160-bit message digest. The input is processed in 512-bit blocks. Figure 1 shows the overall processing of a message to produce a digest. The processing consists of the following steps:
Step 1: Append padding bits. The message is padded so that its length is congruent to 448 modulo 512. Padding is always added, even if the message is already of the desired length. Thus, the number of padding bits is in the range of 1 to 512. The padding consists of a single 1 bit followed by the necessary number of 0 bits.
Step 2: Append length. A block of 64 bits is appended to the message. This block is treated as an unsigned 64-bit integer and contains the length of the original message (before the padding).
The outcome of the first two steps yields a message that is an integer multiple of 512 bits in length. The figure represents the expanded message as the sequence of 512-bit blocks Y0, Y1...YL-1, so that the total length of the expanded message is Lx512 bits. Equivalently, the result is a multiple of 16 32-bit words. Let M[0...N-1] denote the words of the resulting message, with N being an integer multiple of 16. Thus N=Lx16.
Step 3: Initialize MD buffer. A 160-bit buffer is used to hold intermediate and final results of the hash function. The buffer can be represented as five 32-bit registers (A,B,C,D,E). These registers are initialized to the following hexadecimal values (high-order octets first):
A=67452301
B=EFCDAB89
C=98BADCFE
D=10325476
E=C3D2E1F0
Note that each round takes as input the current 512-bit block being processed (Yq) and the 160-bit buffer value ABCDE, and updates the contents of the buffer. Each round also makes use of an additive constant Kt. Only four distinct constants are used. The values, in hexadecimal, are shown in Figure 3.
Overall, for block Yq, the algorithm takes Yq and an intermediate digest value MDq as inputs. MDq is placed into buffer ABCDE. The output of the 80th step is added to MDq to produce MDq+1. The addition is done independently for each of the five words in the buffer with each of the corresponding words in MDq, using addition modulo 232.
Step 5: Output. After all L 512-bit blocks have been processed, the output from the Lth stage is the 160-bit message digest.
In the logic of each round, each round is of the form:
A,B,C,D,E <- [CLS5(A)+ft(B,C,D)+E+Wt+Kt],A, CLS30(B),C,D
where A,B,C,D,E=the five words of the buffer; t=round, or step, number; 0 <= t <= 79; ft=a primitive logical function; CLSs=circular left shift (rotation) of the 32-bit argument by s bits; Wt=a 32-bit word derived from the current 512-bit input block; and Kt=an additive constant. Four distinct values are used, and +=addition modulo 232.
Each primitive function takes three 32-bit words as input and produces a 32-bit word output. Each function performs a set of bitwise-logical operations; that is, the nth bit of the output is a function of the nth bit of the three inputs. The functions are in Table 1. As you can see, only three different functions are used. For 0 <= t <= 19, the function is the conditional function: If B then C else D. For 20<=t<=39 and 60<=t<=79, the function produces a parity bit. For 40<=t<=59, the function is True if two or three of the arguments are True.
It remains to indicate how the 32-bit word values, Wt, are derived from the 512-bit message. The first 16 values of Wt are taken directly from the 16 words of the current block. The remaining values are defined as:
Wt=Wt-16Wt-14Wt-8Wt-3
Thus, in the first 16 rounds of processing, the input from the message block consists of a single 32-bit word from that block. For the remaining 64 rounds, the input consists of the XOR of a number of the words from the message block.
SHA can be summarized as:
MD0=IV
MDq+1=SUM32(MDq, ABCDEq)
MD=MDL-1
SHA has the property that every bit of the hash code is a function of every bit in the input. The complex repetition of the basic function ft produces well-mixed results; that is, it is unlikely that two messages chosen at random, even if they exhibit similar regularities, will have the same hash code. Unless there is some hidden weakness in SHA, which has not so far been published, the difficulty of coming up with two messages having the same message digest is on the order of 280 operations, while the difficulty of finding a message with a given digest is on the order of 2160 operations.
0<=t<=19 Kt=5A827999 20<=t<=39 Kt=6ED9EBA1 40<=t<=59 Kt=8F1BBCDC 60<=t<=79 Kt=CA62C1D6
Round ft(B,C,D)
--------------------------------------
(0<=t<=19) (B.C)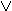 (
(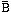 .D)
(20<=t<=39) BCD
(40<=t<=59) (B.C)(B.D)(C.D)
(60<=t<=79) BCD
.D)
(20<=t<=39) BCD
(40<=t<=59) (B.C)(B.D)(C.D)
(60<=t<=79) BCD
Copyright © 1994, Dr. Dobb's Journal