LETTERS
Dear DDJ,
Michael Swaine's flame "Beyond Bablegate" (November 1991) contained more overloaded operators than he thought. Actually, "the latest Applegate in the making" pertains neither to copy protection nor to a hardware company. Applegate could be construed as an AppleGate, however, in that it opens a significant WindowsGate. Applegate Software's OptiMem for Windows is a DLL that solves Windows memory problems--"gates" as formidable as any that shackle Windows applications.
Arthur D. Applegate
Applegate Software
Redmond, Washington
Dear DDJ,
A few comments on Michael Swaine's enjoyable Babblegate piece in his "Swaine's Flames" (November 1991). I too had the pleasure of technically reviewing the manuscript of John Barry's Technobabble (MIT Press, 1991) and share Michael's belief that it will help us all to do gooder English. However, it is unfair to John, to the terminological and sociolinguistic professions, and to our noble language to describe this entertaining book as scholarly. For example, Webster III gives three meanings for the verb to mouse dating back to the 16th century if not earlier. That babbler, W. Shakespeare, wrote "death feasts, mousing the flesh of men," and the Restoration dramatist Wycherley (1641-1715) tells of "naughty women whom they toused and moused." Similarly, to version (vt), meaning "to make a version of" has a well-attested heritage, predating the DP industry by many centuries. "Parts of speech" are identified from usage, not imposed by elitist axioms on morphological structure. Natural language has always and will always confound the prescriptive grammarians. Each generation's "standard" English is a ratbag of "useful solecisms" surviving from earlier generations.
Ironically, both Michael and John are alarmed by what they see as excessive in the computer industry, whereas the real problem is the lack of neologisms for genuinely new concepts. Apart from acronyms-as-words (another device as ancient as written language), the DP lexicon has coined very few original terms (byte and software spring to mind), preferring to coopt and overload lexemes from other, often anthropocentric, vocabularies. It is this polysemous glut of objects, memories (extended and expanded, but which is which?), platforms, and the like, which leads to imprecision and misunderstanding. John Barry often complains about synonyms, but these are not the culprits. Independent discoveries naturally attract a slew of distinct descriptors (many-one mappings) with no ambiguity. Eventually, one of the terms (the best!) usually dominates. It's the one-many mess (take the term static in C/C++, please) that confounds our discourse and documentation unless we remain vigilant.
While on the subject of DP English, may I comment on some phrases in the well-written PenPoint article by Ray Valdes? In "the ability to mount and dismount volumes," I think I prefer dismount to the more prevalent unmount. The rider/disk dismounts [from] the horse/system leaving all four unmounted! In "the coding of message sends," we have a construct similar to that discussed by Michael: "The install is straightforward." "Message sends" may offend the purist, but I see it as technically precise (send as a function name) and economical. I also like "front-ending the team with high-powered talent," as a colorful and effective antianthropomorphism. I have two tiny qualms over "detachable networking reconnectable volumes without peer in mainframe environments." Not just the ever-present, vacuous environment, but the potential ambiguity of peer when used in a networking context.
Stan Kelly-Bootle
Mill Valley, California
Dear DDJ,
Howard Davis's rambling defense of software patents ("Letter," November 1991) is wrong on almost every point. In particular, software patents were formerly disallowed becuase algorithms were thought to be in the realm of abstract ideas--not because of a lack of utility. When the Supreme Court ruled patents may cover algorithms, it was not based on constitutional grounds as Davis asserts.
The U.S. Constitution says in Article I, Section 8, "The Congress shall have power to promote the progress of science and useful arts, by securing for limited times to authors and inventors the exclusive right to their respective writings and discoveries."
This is the basis of copyright and patent law, and the League for Programming Freedom has no quarrel with it. Congress revises the criteria for patents from time to time, and has always exempted mathematical formulas and laws of nature on the theory that ownership of these would not promote progress. At issue is whether algorithms implemented in software are in the same category.
We've had ten years of software patents now. Does anyone seriously think any patents have promoted progress?
Roger Schlafly
Soquel, California
Dear DDJ,
This is in reply to the letter from Howard Davis in your November 1991 issue.
Sorry to burst your delusion, Mr. Davis, but computers have been able to display text since before the 1960's. I might laud a more efficient method of displaying text, but displaying text is not a new innovation in computer software.
I'm a relatively new subscriber to DDJ, so I didn't get to read that article by the League for Programming Freedom, but from the tone of your letter, they seem like a fine bunch of people to me! Computer software, dispite the fact that when "read" to a computer it can make that computer behave in different ways, is written matter no different from the work of a novelist or poet. Being written matter, there is nothing there to patent! You can no more patent software than a novelist can patent a book. Claiming that, because your software is so unique makes it patentable, is akin to a writer discovering and patenting a genre that no other writer has explored before.
So even without reading the LPF's article, I would concur that patenting software is patently absurd.
Bernie Gallagher
Somerset, New Jersey
Dear DDJ,
Your magazine has always been helpful to me as a programmer, and perhaps you or one of your readers may be able to help me locate an algorithm to send voice through the IBM PC's speaker.
A common way to reproduce voice is to feed the AM signal into an 8-bit A-to-D converter, which is then sampled and the values stored in sequential order. To "play back," the values are sent to a D-to-A converter, which reproduces the voice accurately enough to recognize a person's voice.
Unfortunately, the PC's speaker is driven by digital logic circuitry and current is either on or off in the speaker coil. It is impossible, therefore, to send an AM signal to the PC's speaker. However, one can send a constant amplitude, variable-width pulse train. The algorithm I need would convert a string of 8-bit numbers representing an AM signal into a list of numbers representing the variable-width string of pulses the PC's speaker needs, with minimal loss of information.
From what I have been able to gather, the AM waveform needs some high pass filtering and then is sent through a differentiater. The output should be a logical O if the differentiater's output is positive and 1 if negative. While it is easy to see how to build such a system in hardware, I want to do it with software. Using the 8-bit code representing the AM information as input, how does one get the "differentiated" output? The speech type program found in shareware sources have not been of much help. Can someone point me in the right direction?
Theron Wierenga
Muskegon, Michigan
Dear DDJ,
In his July 1991 "Structured Programming" column, Jeff Dentemann presents a technique for detecting the presence of a serial port. From our experience with the popular German asynch toolbox V.24 Tools Plus, let me add some thoughts and hints.
First, I recommend not to use the UART's loopback mode at all. Why? Simply because this mode is faulty in about 10-20 percent of all 8250s all over the world. The problem with the loopback mode has to do with the interrupt line: With interrupts enabled, some UARTs fail to generate an interrupt request even when you can read in the Interrupt ID Register (IIR) that the chip detected an interrupt-causing event. The software-related problem of this is that it's not easy to recover from this situation. Although Jeff doesn't use interrupts for reading the response from the UART, a programmer could easily run into this situation when having serial interrupts enabled before calling Jeff's DetectComPort() function. But there is even another argument against using the loopback mode. Some internal modem cards which simulate an 8250 fail to simulate the loopback mode and can even get in an unpredictable state when setting the loopback bit. We experienced this problem with an internal modem for a Toshiba Laptop based on the Sierra chipset.
Second, Jeff's solution only works with true standard PC asynch adapters (COM1..COM4). On the other hand, the programmer is more and more often required to support PS/2s (on which Jeffs code doesn't work for COM3 and (COM4) and even multiport adapters. In order to handle these fairly common situations, you first have to deal with I/O addresses. I/O addresses from multiport adapters (like DigiBoard, AST, etc.) are well-known and can therefore easily be tested using an address table. But when testing some 10P20 I/O ports by simply writing certain bytes to the port and expecting other bytes in return, you can easily lock up the computer. Why is this? Because if there is another board located at the specific I/O address than the expected asynch adapter, you will easily set this guy in an unpredictable state by writing (for this board) random byte values.
To get around this, it is wise first to make sure by read-only port accesses that there is a good chance for an asynch adapter at that specific location. If all read-only tests pass, we write a value to the divisor latch port and then simply read it back. This is, in essence, the same as setting a specific baud rate and then verifying that the baud rate could be set. The sequence of events is shown in Example 1. (I use pseudocode because I refuse to write in Turbo Pascal.)
get a base I/O address.
read the value of the Interrupt Enable Register.
if bit 4,5,6, or 7 in the Interrupt Enable Register is set, this can't be a UART.
read the value of the Modem Control Register.
if bit 5,6, or 7 in the Modem Control Register is set, this can't be a UART.
read the value of the Interrupt Identification Register.
if bit 4 or 5 in the Interrupt Identification Register is set, this can't be a UART.
try to set 19.200 bps.
read the current baud rate.
if the current baud rate is 19.200 pbs, there is a UART at this base I/O address.
Even if multiport adapters don't need to be supported, an application should use additional code to obtain valid base I/O addresses in order to make proper use of COM3 AND COM4 in a PS/2. The problem with the PS/2 is that IBM decided not to use 03e8H and 02e8H (the standard PC values) for COM3 and COM4, but 322OH and 3228H instead. One can easily test if there is a chance for these I/O addresses by reading the BIOS data area. The PS/2 BIOS loads the data area at offset 0040H:OOOOH with the I/O addresses of all installed asynch adapters at boot time, so peeking into this area can tell whether it makes sense to test for a PS/2 asynch adapter or not. Since the PC BIOS fills this area with Os if it is too dumb to detect COM3 and COM4, the logic in Example 2 will present you the base addresses of COM1..COM4 on PCs and PS/2s.
peek into the BIOS data area at offset 0040H:x, where x is O for COM1, 1
for COM2, 2 for COM3, and 3 for COM4.
if there is a value unequal zero, return it as the base address.
if the value is zero, return 03f8H for COM1, 02f8H for COM2, 038H for
COM3, and 03f8H for COM4.
One last hint with regard to the PS/2: IBM not only chose nonstandard base addresses for COM3 and COM4, but a nonstandard IRQ for COM3, as well. On the PS/2, COM3 uses IRQ3, just like COM2 and COM4. It is therefore wise to use a statement such as
if the base address for COM3 is 3220H,
then use IRQ3
otherwise, use IRQ4.
to properly set up asynch interrupts.
The logic presented here has been used by our customers on several thousand PCs and has not been reported to have failed even once.
Ralph Langner
Hamburg, Germany
Dear DDJ,
The interest in the obscure application of matrix multiplication to the computation of Fibonacci series has been surprising, to say the least! (see the September and October "Letters" columns for responses to my June article, "Effeciently Raising Matricies to an Integer Power.") I was very glad to see that many readers were aware of the direct method for computing the golden ratio and the individual elements of a Fibonacci series. Several readers pointed out the equations shown in Example 3 and noted that they can be simplified by precomputing some of the terms. These methods are well documented in literature and I was aware of them.
However, programmer (including myself) beware of using floating-point arithmetic to compute integer results. For instance, the 80x87 math coprocessor guarantees the precision of floating-point operations up to 15 decimal places only. This may seem sufficient, until you realize how fast Fibonacci numbers grow. In fact, Fibonacci(71) and greater, are beyond the accuracy of the 80x87 math coprocessor.
/\
Fi =  i - i
i - i
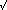 5
= 1 + 5 = 1.61803...
2
/\
= 1 - 5 = -0.61803...
2
5
= 1 + 5 = 1.61803...
2
/\
= 1 - 5 = -0.61803...
2
This is illustrated in Listing One: The program simply compares the Fibonacci number computed using various methods. When Fibonacci numbers greater than 71 are computed, small differences that are caused by inaccuracies of the floating-point computations become apparent.
Thus, a better way to compute Fibonacci numbers would be to come up with an integer algorithm that dynamically expands the number of bits used in the computation, on as needed basis; or, simply overkill by using some large number of bits (like 512 or 1024); or, precompute the floating-point constants and then come up with a software emulation of higher-precision floating-point operations; or, come up with an algorithm that always produces enough precision to guarantee an accurate integer result (since that's all we need for Fibonacci number computations).
Victor J. Duvanenko
Indianapolis, Indiana
Copyright © 1992, Dr. Dobb's Journal