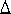 wij = vaioj where v is the learning rate that specifies a scaling factor for changes during training.
wij = vaioj where v is the learning rate that specifies a scaling factor for changes during training.
Jeannette (Jet) Lawrence is technical publications manager at California Scientific Software, and the author of their 1989 publication Introduction to Neural Networks. She can be contacted at 160 E. Montecito #E, Sierra Madre, CA 91024.
Neural networks, which are formed by simulated neurons connected together much the same way the brain's neurons are, are able to associate and generalize without rules. They have been used to classify undersea sonar returns, speech, and handwriting, predict financial trends, evaluate personnel data, control robot arms, model cognitive phenomena, and much more.
The kinds of problems best solved by neural networks are also those that people do well: Association, evaluation, and pattern recognition. Neural networks also handle problems that are difficult to compute and do not require perfect answers -- just quick, good answers. This is especially true in real-time robotics or industrial controller applications.
Other appropriate applications are predicting behavior and analyzing large amounts of data, such as in stock market forecasting and consumer loan analysis. New applications under development include simple vision systems, weather forecasting, assistance in medical diagnosis, and estimation of the worth of insurance claims.
A neural network is not always the best solution for certain problems. They are poor at precise calculations and serial processing, nor are they able to predict or recognize anything that does not inherently contain some sort of pattern. This is why, for example, a neural net cannot predict the lottery, because a lottery is by definition a random process.
It is unlikely that a neural network could be built that has the capacity to think as well as a person does for two reasons: Neural networks are terrible at deduction (logical thinking), and the human brain is too massively complex to simulate completely. A human brain contains about 100 billion neurons, each of which connects to about 10,000 other neurons.
A brief look at the general structure and operation of neural networks will help explain the limits of neural networks abilities. There are many types of neural networks, but all have three things in common: Distributed processing elements (neurons), the connections between them (network topology), and the learning rule. These three aspects together constitute the neural-network paradigm.
Artificial neurons are also known as processing elements, neurodes, units, or cells. Figure 1 shows the canonical model of a neuron. Each neuron receives the output signals from many other neurons. The point where two neurons communicate is called a "connection." This neural connection is analogous to a biological synapse in the mammalian brain. A neuron calculates its output by finding the weighted sum of its inputs. The strength of a particular connection, called its weight, is noted wij, where i is the receiving neuron and j is the sending neuron.
At any point in time (t), the activation function, adds up the weighted inputs to produce an activation value ai(t). In most models, input signals can either be excitatory or inhibitory, that is, they either tend to make the neuron fire or tend to suppress its firing. This value is passed through an output (or transfer) function fi, which produces the actual output for that neuron for that time, oi(t).
After summation, the net input of the neuron is combined with the previous state of the neuron to produce a new activation value. In the simplest models, the activation function is the weighted sum of the neuron's inputs; the previous state is not taken into account. In more complicated models, the activation function also uses the previous output of the neuron, so that the neuron can self-excite. These activation functions slowly decay over time; an excited state slowly returns to an inactive level. Sometimes the activation function is stochastic, that is, it includes a random noise factor.
The transfer function of a neuron defines how the activation value is output. The earliest models used a linear transfer function. However, certain problems are not entirely reducible by purely linear methods. The threshold transfer function is the simplest of the non-linear models. This function is an all-or-nothing function; if the input is greater than some fixed amount (the threshold), the neuron will output a 1; if the value is below the threshold, the neuron will output a 0.
Sometimes the transfer function is a saturation type of function: More excitation above some maximum firing level has no further effect. A particularly useful transfer function is called the "sigmoid function," which has a high-and a low-saturation limit and a proportionality range in between. This function is 0 when the activation value is a large negative number. The sigmoid function is 1 when the activation value is a large positive number and makes a smooth transition in between.
The behavior of the network depends heavily on the way the neurons are connected. In most models, the individual neurons are grouped into layers so that the output from each neuron in one layer is fully interconnected with the inputs of all the neurons in the next layer. A network may include inhibitory connections from one neuron to the rest of the neurons in the same layer called "lateral inhibition." Sometimes a network has such strong lateral inhibition that only one neuron in a layer, usually the output layer, can be activated at a time. This effect of minimizing the number of active neurons is known as "competition." In a feed-forward network, neurons in a given layer do not take inputs from subsequent layers or from layers prior to the immediately previous layer. Also, the neurons in a feed-forward network usually do not connect to each other. The back propagation network typically has three feed-forward layers: Input, hidden, and output. Feedback models additionally include connections from the outputs of one layer to the inputs of the same or a previous layer.
A neural network learns by adapting to changes in the input. This is accomplished through changes in the weights as the network gains experience. The learning rule is the very heart of a neural network; it determines how the weights are adjusted as the neural network gains experience. Of the numerous learning rules in use, the most well-known are Hebb's Rule and the Delta Rule. Nearly all other rules are variations of these two.
More than 30 years ago, Donald O. Hebb theorized that biological associative memory lies in the synaptic connections between nerve cells, and that the process of learning and memory storage involved changes in the strength with which nerve signals are transmitted across individual synapses. Hebb's Rule states that pairs of neurons that are active simultaneously become stronger by synaptic (weight) changes. The result is a reinforcement of those pathways in the brain. Hebb's Rule states wij = vaioj where v is the learning rate that specifies a scaling factor for changes during training.
The Delta Rule, a supervised learning algorithm, additionally states that if there is a difference between the actual output pattern and the desired output pattern during training, then the weights are adjusted to reduce the difference. The Delta Rule states wij = v(ti - ai)oj, where ti is the training (desired output) pattern. The back-propagation rule is a generalization of the Delta Rule for a network with hidden neurons.
The best learning rule to use with linear neurons is the Delta Rule. This allows arbitrary associations to be learned, provided that the inputs are all linearly independent. Other learning rules (such as Hebb's) require that the inputs also be orthogonal.
Neural networks can be arbitrarily categorized by topology, neuron model, and training algorithm. (Figure 2 shows one method of classifying neural networks.) There are two main subdivisions of neural network models: Feed-forward and feedback topologies.
Feedback models can be constructed or trained. In a constructed model the weight matrix is created by taking the outer product of every input pattern vector with itself or with an associated input, and adding up all the outer products. After construction, a partial or inaccurate input pattern can be presented to the network, and after a time the network should converge so that one of the original input patterns is the result. Hopfield and BAM are two well-known constructed feedback models.
The Hopfield network is a self-organizing, associative memory. It is the canonical feedback network. It is composed of a single layer of neurons that act as both output and input. The neurons are symmetrically connected (wij = wji. (See Figure 3.) Hopfield networks are made of nonlinear neurons capable of assuming two output values: -1 (off) and +1 (on). The linear synaptic weights provide global communication of information. In spite of its apparent simplicity, a Hopfield network has considerable computational power.
The weight matrix is created by taking the outer product of each input pattern vector with itself, and adding up all the outer products. After construction, a pattern is given to the network. A process of reaction-stimulation-reaction between neurons occurs until the network settles down into a fixed pattern called a "stable state." Thus, the network result comes as a direct response to input.
The energy required by a device to reach a stable state can be plotted in three dimensions as a curved surface. In this representation, the stable states of the system (the energy minimums) appear as valleys. A neural network, which is used to find "good enough" solutions to optimization problems, may have many possible energy minimums or valleys. Depending upon the initial state of the network, any of the deepest valleys may end up as the answer. Inputing incomplete information to an associative memory network causes the network to follow paths to a nearby energy minimum where the complete information is stored.
Hopfield networks can recognize patterns by matching new inputs with the closest previously stored patterns. Hopfield networks are especially good for finding the best answer out of many possibilities. They are also good at recalling all of a stored piece of information when given partial data. Hopfield networks are often used in applications requiring some form of content addressable memory.
While the Hopfield model is able to associate on a large scale, it does not learn; the weights must be set in advance. A serious limitation of the Hopfield model is that the maximum number of memories M, which can be stored while still retaining perfect recall is [M less than or equal to N/(4 log N)] where N is the number of neurons. If more memories are stored, then the stable states begin to differ significantly from the stored information and eventually all will be forgotten. If an error rate of 5 percent is tolerable, then the capacity is about 14 percent of N. The hardware efficiency is also poor. A variation has been proposed, called the "Unary or Hamming" network, which uses inhibitory lateral connections in the internal neurons. It is claimed that this model has a capacity of M >> N with no errors in the final state.
Bart Kosko brought the Hopfield network to its logical conclusion with the BAM. The BAM (bidirectional associative memory) is a generalization of the Hopfield network. Instead of creating the weight matrix with the dot product of a pattern with itself (auto-association), pairs of patterns are used (pair association). After construction of the weight matrix, either pattern can be applied as input to elicit as output the other pattern in the pair.
A trained feedback model is much more complicated because adjustment of the weights affects the signals as they move forward as well as backward. The Adaptive Resonance Theory (ART) model is a complex trained feedback paradigm developed by Stephen Grossberg and Gail Carpenter of the Center for Adaptive Systems at Boston University. ART is considered by some to be very powerful, but the number of patterns that can be stored is limited to exactly the number of nodes in the storage layer. No production applications have been published to date; ART is presently considered a research tool.
The second division of neural networks is the feed-forward category. The earliest neural network models were linear feed-forward. In 1972, two simultaneous papers independently proposed the same model for an associative memory, the linear associator. J.A. Anderson, a neurophysiologist, and Teuvo Kohonen, an electrical engineer, were not aware of each other's work.
The linear associator uses the simple Hebb's Rule. The only case where association is perfect when simple Hebbian learning is used is when the input patterns are orthogonal. This puts an upper limit on the number of patterns that can be stored. The system will work very well for random patterns if the maximum number of patterns to be stored is 10 - 20 percent of the number of neurons. If the input patterns are not orthogonal, there will be interference among them; fewer patterns can be stored and correctly retrieved. One of the predictions of the linear associator is interference between nonorthogonal patterns. Much of Kohonen's book, Self-Organization and Associative Memory (Springer-Verlag, 1984) is concerned with correcting the errors caused by interference.
The nonlinear feed-forward models are the most commonly used today. Feed-forward networks, for historical reasons, are less often considered to be associative memories than the feedback networks, even though they can provide exactly the same functionality. It can be shown mathematically that any feedback network has an equivalent feed-forward network that performs the same task.
There are two main types of training algorithms: Supervised and unsupervised. Supervised learning is the most elementary form of adaptation. It requires an a priori knowledge of what the result should be. During training, the network's output is compared to the ideal response, and any error is used to correct the network. Learning occurs as a result of changes to the weights to reduce the errors as the network gains experience. For one-layer networks this is easily accomplished by monitoring each neuron individually. In multi-layer networks, supervised learning is more difficult due to the correction of the hidden layers. Unsupervised learning differs in that it does not have specific corrections made by comparison to ideal results. Supervised and unsupervised learning are methods which are used exclusively of each other.
The supervised back propagation model is the most commonly implemented paradigm today because it is the best general-purpose model and probably the best at generalization. (This model is used by the "BrainMaker" software from California Scientific Software.) Back propagation is a multi-layer feed-forward network that uses the Generalized Delta Rule.
By 1985, back propagation had been simultaneously discovered by three groups of people: D.E. Rumelhart, G.E. Hinton, R.J. Williams; Y. Le Cun; and D. Parker. Back propagation is the canonical feed-forward network where an error signal is fed back through the network, altering weights as it goes, in order to prevent the same error from happening again. (See Figure 4.)
The error on an output neuron, i, for a particular pattern, p, is defined as Epi = (Tpi - Opi) where T is the training (desired) pattern and O is the actual output. The total error on pattern p, Ep, is the sum of the errors on all the output neurons for pattern p. The total error, E, for all patterns is the sum of the errors on each pattern over all p. The simplest method for finding the minimum of E is known as "gradient descent." It involves moving a small step down the local gradient of the scalar field. This is directly analogous to a skier always moving down hill through the mountains until he hits the bottom.
Back propagation is useful because it provides a mathematical explanation for the dynamics of the learning process. It is also very consistent and reliable in the kinds of applications that can currently be built. The biggest limitation is the size of the network. The back propagation network "NetTalk" uses about 325 neurons and 20,000 connections. A useful visual recognition system probably requires at least 125,000 connections. Currently available commercial systems provide anywhere from a few neurons and connections to 1 million neurons and 1.5 million connections, for anywhere from $200 to $25,000.
A popular unsupervised feed-forward model is the Kohonen model. The basic system is a one- or two-dimensional array of threshold-type logic units with short-range lateral connections between neighboring neurons. The system modifies itself so that nearby neurons respond similarly. The neurons compete in a modified winner-take-all manner. The neuron whose weight vector generates the largest dot product with the input vector is the winner and is permitted to output. In this model not only the weights of the winner but also those of its nearest neighbors (in the physical sense) are adjusted.
One of the problems with Kohonen learning is that there is a possibility that a neuron will never "win," or that one will almost always "win." The weight vectors get stuck in isolated regions. One way to prevent the weight vectors from getting stuck is to start off with all the weight vectors equal. The network is first fed fractional amounts of the patterns. The inputs are then slowly built up to the full input patterns. This method, called "convex combination," works well but it slows down learning. Another preventative method is to add noise to the data, which makes the probability density function positive everywhere. The probability density function is a real-valued function that gives the probability that a random variable has values in the set. This method works, but it is even slower than convex combination. Another approach is to give the neurons a "conscience"; if the neurons realize that they are winning a lot, they will step out of the competition for a while.
A special case of the feed-forward model is the Neocognitron. The original model was unsupervised, but a more recent model (1983) uses a teacher. The multi-layer (seven- or nine-layer) system assumes that the builder of the network knows roughly what kind of result is wanted. All the neurons are of analog type; the inputs and outputs take nonnegative values proportional to the instantaneous firing frequencies of actual biological neurons. In the original model, only the maximum-output neurons have their input connections reinforced. It uses a variation of the Hebbian Rule. After learning is completed, the final Neocognitron system is capable of recognizing handwritten numerals presented in any visual field location, even with considerable distortion. Drawbacks of the Neocognitron are that it is highly specialized and requires a large number of neurons and connections.
Neural networks are capable of some impressive things but they are also limited, primarily by the size of the network and the complexity of the problem. They are especially good at association and generalization, but poor at precise computations and logic. Some models are able to generalize better than others, some are good at association.
With more than 40 functioning models to choose from, it is important to know which models have had the most success and to understand their similarities and differences. Currently, back propagation is the most popular model. Several others are discussed in detail in this issue, each has it own merits.