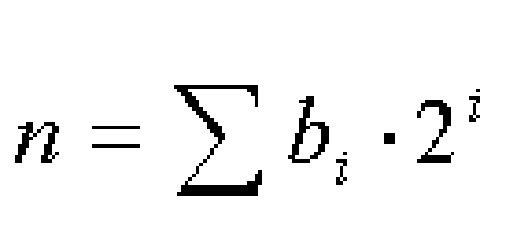
This just in: David Vandervoorde and Nicolai Josuttis' book on C++ templates is out [1]. Read it.
Matrix operator+(const Matrix& lhs,
const Matrix& rhs)
{
int n = lhs.NumRows();
int m = lhs.NumCols();
assert(rhs.NumRows() == n);
assert(rhs.NumCols() == m);
Matrix sum(n, m);
for(int i=0; i<n; ++i)
for(int j=0; j<m; ++j)
sum[i][j] =
lhs[i][j] + rhs[i][j];
return sum;
}
Once the matrix data and operations have been encapsulated like this, code that
deals with matrices and matrix expressions will look as simple as this:
C = A + B; C = A * B; D = A + B + C;That is certainly quite an achievement. The advocates of object-oriented programming are beaming with pride, and rightfully so. The problem with all this is that the people who are most likely to work with matrices in their programs (namely, those who implement massive amounts of number crunching) wouldn't touch this code with a 10-foot mouse cursor. To see why, look at the third line of code above, where the sum of the three matrices A, B, and C is assigned to D. You don't have to analyze the machine code to agree that this code is not acceptable to someone for whom a few machine instructions more or less make the difference between success and failure. What is happening here is that a temporary matrix object is constructed to hold the sum of A and B. The sum of this temporary matrix object and the matrix C is placed in a second temporary, which is then assigned to D. It is clear that the creation and destruction of these temporary objects is pure overhead. Moreover, the code iterates over the n x m matrix positions three times, whereas a handwritten loop would need only one iteration.
It was not until quite recently that people have come up with C++ programming techniques that make it possible to generate optimized machine code while retaining the advantages of object-oriented programming on the source-code level. Today, there are C++ libraries for numerical computation whose performance equals or even surpasses that of traditional Fortran libraries. Examples are Blitz [2], POOMA [3] (described in CUJ a few months back [4]), and the Matrix Template Library [5]. A comprehensive discussion of the ideas and techniques that these libraries use is far beyond the scope of this column. On the other hand, since much of the progress that has been made is based on templates and template metaprogramming, it is appropriate for me to give you at least some idea of what's going on there. It is true that the majority of you will never come in contact with these techniques, and those who do are much more likely to use them indirectly, through someone else's library, rather than in their own code. On the other hand, it is a time-honored and proven principle of our education system that people should know and understand a little more than they absolutely have to for their daily work. Therefore, in this and the next column, I'll show you how template and template metaprogramming techniques can be applied to generate efficient code, thus making C++ a competitive language choice for scientific and numerical programming.
The most important tool for efficient numerical programming with C++ is "expression templates." I'll get to that in my next column. This month's column is hardly more than a little warm-up. I will discuss a relatively simple, but nonetheless important, template technique for generating efficient code -- namely, loop unrolling.
template<typename T>
T DumbPower(T base, int exp) {
assert( 0 <= exp );
T pow = T(1);
for(int i=0; i<exp; ++i){
pow *= base;
}
return pow;
}
For this function to compile, we must require that type T have a constructor
from int and overloaded operator*=, which should of course be based
on an overloaded operator*. For the function to be meaningful, we must
also require that:
T(1) * x = x * T(1) = xfor all objects x of type T, and that:
(x * y) * z = x * (y * z)for all objects x, y, and z of type T. Mixing terminology from mathematics and from generic programming, this can be expressed by saying that type T must model the concept of a multiplicative monoid with neutral element T(1).
So what kind of optimization on the machine-code level can we hope to achieve here, and how can template metaprogramming techniques help us out? Before I get to the answer, I must climb on my mathematician's soapbox and lecture you on the subject of algorithm complexity. Judging from some of the C++ code I've seen recently, specifically code that uses the STL, it seems to me that many C++ programmers fail to grasp the enormity of the difference in performance between algorithms of different complexity. A case in point is the linear STL algorithm std::find as opposed to the logarithmic member function find of std::map or std::set. Another good example is the calculation of the nth power of a number or an algebraic object. The algorithm DumbPower above uses exactly n multiplications to calculate xn. Suppose we need to calculate xn where n equals 232, and assume that one multiplication takes .001 seconds to perform. Since numerical programs often work with very large objects, such as huge matrices, this is by no means an unrealistic assumption. The cost of the multiplications in the algorithm DumbPower would be 232 * .001 seconds, which comes out to be approximately 50 days. Rather than starting with x and then multiplying by x (232 - 1) times, we could also calculate the desired result by starting with x and then squaring 32 times, thus employing a logarithmic algorithm rather than a linear one. The total cost of the multiplications would then be .032 seconds instead of 50 days. But the real beauty lies not in the difference between .032 seconds and 50 days. The real beauty lies in the way that this scales. Suppose we need to raise x to the power 264 instead of 232. In the logarithmic approach, the cost of multiplication doubles, from .032 to .064 seconds. In the linear approach, the cost goes from 50 days to approximately 585 million years, which is about one-tenth of the age of our planet. Moral of the story: optimize your algorithms before you optimize your machine code.
The logarithmic approach can be used to calculate xn for arbitrary natural numbers n, not just those that happen to be powers of two. We'll look at that algorithm in just a moment. Let's stick with DumbPower for now, as a simple example for discussing loop unrolling. Loop unrolling is an optimization that comes into play when the number of iterations through a loop (the exponent exp in our example) is known at compile time. Admittedly, this is a very special case, but it is not unheard of in scientific computing. For example, calculations in physics often contain loops that iterate over the three dimensions of ordinary space, or the four dimensions of a time-space continuum. In those cases, the machine instructions that implement the for-loop are time overhead. One could instead write code that simply repeats the body of the loop as many times as needed. In our example, the for-loop in DumbPower would be replaced with a repetition of the one-line body of the loop:
pow *= base; pow *= base; . . . pow *= base;This technique has turned out to be instrumental in improving the performance of scientific programs. Therefore, it would be very desirable to have a C++ metaprogram that generates the appropriate number of repetitions of the for-loop's body at compile time. Listing 1 shows how this is done. The idea is to make DumbPower an inline function template and pass the exponent as an integer template argument. The function achieves the effect of the original for-loop by calling another instantiation of itself, with the exponent decremented by one. Ignoring the ExpTag gimmick for now, look at the body of UnrolledDumbPowerInternal in Listing 1. Conceptually, the call:
UnrolledDumbPowerInternal(
base,
ExpTag<exp-1>()
)
is a recursive call. Since the body of UnrolledPowerInternal consists of
just one line, a multiplication, and because it is an inline function, each of
these "recursive calls" amounts to the generation of one line of code, a multiplication.
The recursion ends when the exponent has come down to 1, because UnrolledDumbPowerInternal
is overloaded for exp = 1. This is where our assumption that the exponent
is known at compile time really plays out. If you have any doubts whether this
really unrolls the loop, put the line:
cout << UnrolledDumbPower<5>(42);into your main and inspect the generated machine code.
ExpTag in Listing 1 remains to be explained. The top-level function UnrolledDumbPower takes the exponent as an integer template argument so that the client can use the convenient syntax:
UnrolledDumbPower<exp>(base);In order to give special treatment to the case exp = 1, we would need a partial specialization of the function template UnrolledDumbPower, with exp set to 1 and T left unspecified. But that is not possible. There is no such thing as partial specialization of function templates in C++. There are only explicit specializations and overloads. (For a complete discussion of this intriguing subject, see Herb Sutter's article [6].) There is a standard trick to solve this dilemma. The top-level function defers all its work to an internal helper function. The helper function takes an additional argument whose type is a dummy class template, ExpTag in this case, whose only purpose in life is to provide different types for different integers. The internal helper function can then be overloaded for special instantiations of the dummy class template. For example, look at the two overloads of UnrolledDumbPowerInternal at the end of Listing 1. These are overloads for the case where the second argument is of type ExpTag<1> and ExpTag<0>, respectively. The net effect of this is that we have faked a partial specialization of the original function UnrolledDumbPower for special values of the integer template argument exp.
Two remarks are in order. Firstly, loop unrolling via function templates relies on inlining. Compilers usually have a limit on the inlining depth. If you try to unroll a loop that has more iterations than this limit, then you get function calls, which are probably worse than the overhead you would get from the original loop. (You may want to play with the UnrolledDumbPower example to see that happening.) Therefore, this technique requires that you gain knowledge or take control of your compiler's inlining depth. Secondly, there comes a point where the space overhead of the unrolled loops turns into a nasty new time overhead (namely, when the execution of the unrolled loop statements starts creating page faults). Therefore, loops with many iterations should be only partially unrolled. This means that the original loop with x iterations should be replaced by a loop with y iterations whose body consists of x/y repetitions of the original loop body. Following or preceding this new loop, you then place another r repetitions of the original loop body, where r is the remainder of x upon division by y. As always with this kind of optimization, there can be no general rules as to when and how all this should be done. We're deep into heuristics territory here.
Now let's go back to the logarithmic algorithm for calculating the nth power. For arbitrary exponent n, this is how it works. First, calculate the binary representation of n:
where each bi is either zero or one. Since x(a+b) = xa * xb, the power xn can now be written as follows:
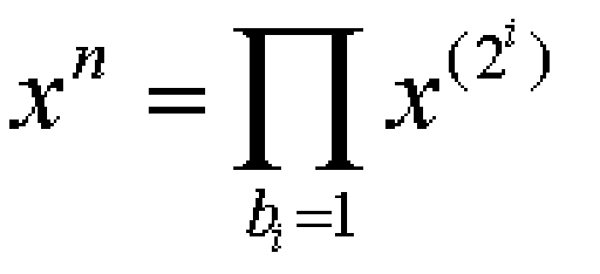
Therefore, what the algorithm does is to square the base x enough times and, as it goes along, multiply the appropriate powers of x into the end result. Needless to say, in practice, you would not calculate the binary representation of the exponent separately and store it. The calculations of the binary representation and the end result can be combined, as shown in Listing 2. For some obscure reason, this algorithm is known in computational mathematics as the Russian peasant algorithm.
Listing 3 shows how the loop in the function Power of Listing 2 can be unrolled. The function template UnrolledPowerInternal, which is being recursively inlined here, consists of a three-pronged if-statement. That seems horrible at first, because it looks as if after unrolling, this if-statement will now be repeated for each iteration through the loop. However, the condition on which the if-statement branches is known at compile time. Therefore, an optimizing compiler can be expected to throw out the dead branches. If you have enough knowledge or control of your compiler to guarantee this, then this is a very elegant solution. Notice how it also makes it much easier to fake the partial specialization of the function template UnrolledPowerInternal for exp=1: the special case is handled in the if-statement. If, for some reason, you cannot rely on this compiler optimization, then you must turn the if-branching in UnrolledPowerInternal into a compile-time if. That can be achieved by using static member functions instead of non-member functions such as UnrolledPowerInternal. You can then select the function to be called at compile time because you can select the appropriate class via the if-construct that is available in C++ template metaprogramming.
template<typename TL, int n>
class MetaNthType {
public:
typedef MetaNthType<typename TL::Tail, n-1 >::Ret Ret;
};
The typedef in there is of the general form:
typedef X::y z;where X is a type expression that depends on a template parameter (TL in this case). Therefore, X::y is a dependent type and must be preceded with the typename keyword:
typedef typename MetaNthType<typename TL::Tail, n-1 >::Ret Ret;
[2] <www.oonumerics.org>
[3] <www.acl.lanl.gov/pooma>
[4] Jeffrey D. Oldham. "Scientific Computing Using POOMA," C/C++ Users Journal, November 2002.
[5] <www.nsc.nd.edu>
[6] Herb Sutter. "Sutter's Mill: Why not Specialize Function Templates?" C/C++ Users Journal, July 2001.