Introduction
Neural networks are a fascinating set of tools capable of solving a variety of complex problems. The class of AI (artificial intelligence) algorithms known as neural networks is somewhat broad. In the past, much attention has been focused on just one type of these algorithms, the BP (backpropagation) neural-network. The BP neural network learns relationships between a set of input and output patterns and can then intelligently respond to new inputs using the experience it gained during training. The BP network is part of the supervised learning class of neural networks, since the error signal it produces during training is used to supervise the learning process. Neural networks utilizing supervised learning techniques, like the BP network, have proven themselves in many practical applications such as classification, generalization, and prediction. However, having to know the desired output for each input pattern before training begins is often a prohibiting limitation.
When the desired outputs for the training input patterns are unknown, it would be nice if the neural network could learn the relationships (whatever they may be) on its own. Another type of neural network using an unsupervised learning technique, called the SON (self-organizing neural network), provides an ideal solution. This article shows how simple the SON is to implement, how it can be used to categorize data, and its power as a statistical modeling tool.
Network Architecture
As shown in Figure 1, the SON is composed of two layers: an input layer and a Kohonen layer (named after the network's creator Teuvo Kohonen). The input layer can be represented as a vector whose components correspond to the input-layer node values:
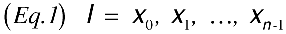
where n is the number of input-layer nodes.
Since the input patterns in the training set populate the input-layer node values, the training set is implemented as an array of input vectors:
// Training set patterns double pattern[MAX_NUM_PATTERNS] [MAX_INPUT_NODES]; int num_patterns; // Number of training patterns int num_input_node; // Nodes in the Input Layer
The Kohonen layer is a collection of nodes arranged in a tabular format. A weighted link exists between each input node and Kohonen-layer node. The link values, which are modified during the training process, represent the state of the network. Weight vectors for each Kohonen-layer node can be created from the link values connecting it to the input nodes:
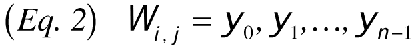
where i and j are the row and column numbers of the Kohonen-layer node, and n is the number of nodes in the input layer.
The weight vectors can be implemented in a variety of ways. However, when their size is not too large, a three-dimensional array is the easiest:
// Weight vectors double W[MAX_ROWS][MAX_COLS][MAX_INPUT_NODES];
Training the SON
Before training begins, all input pattern components are scaled between 0.0 and 1.0 so that no one component dominates a pattern and interferes with the SON's learning process. The weight vectors are then initialized to random values between 0.0 and 1.0. This task can be accomplished with the Initialize_Weights function:
void
Initialize_Weights
(double W[MAX_ROWS][MAX_COLS]
[MAX_INPUT_NODES],
int rows, int cols,
int num_input_nodes )
{
int i,j,k;
// Initialize each weight vector component
// to a value between 0.0 and 1.0
for (i=0; i<rows; i++)
for (j=0; j<cols; j++)
for (k=0;k<num_input_nodes;k++)
W[i][j][k]=
((double)rand()/
(double)RAND_MAX);
}
Learning occurs during a training procedure in which the input training patterns are repeatedly presented to the network. As each pattern is presented, the nodes in the Kohonen layer compete to see which ones get to participate in the learning process. For a given input pattern, computing the Euclidean distance between the input vector and each node's weight vector determines the winning node:
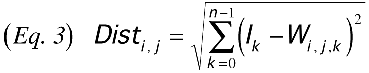
where i and j are the row and column of the node in the Kohonen layer, and n is the number of nodes in the input layer.
The Kohonen-layer node with the shortest distance is the winner and is identified by its row and column position. The Get_Winning_Node function finds the position of the winning node in the Kohonen layer:
void
Get_Winning_Node(double pattern[],
double W[MAX_ROWS][MAX_COLS]
[MAX_INPUT_NODES],
int num_input_nodes, int rows,
int cols,
int *winning_row, int *winning_col )
{
double value;
double min_value=9999999;
double sum=0;
int i,j,k;
// Find the Kohonen Node with the shortest distance
for (i=0; i<rows; i++)
for (j=0; j<cols; j++)
{
value=0;
// Find the distance between the Input vector
// and the current Kohonen node (i,j)
for (k=0;k<num_input_nodes;k++)
value+=pow(pattern[k]-
W[i][j][k],2);
value=sqrt(value);
// If the Kohonen node value is less than the
// smallest seen, store it in position (i,j)
if (value<min_value)
{
min_value=value;
*winning_row=i;
*winning_col=j;
}
}
}
In biological neural networks, a stimulus excites neurons. Through lateral interaction, this stimulus propagates outward to the surrounding neurons. Figure 2 illustrates the amount of excitation experienced by the surrounding neurons, which can be approximated by what is called the "Mexican Hat" function. The greater the distance from the excited neuron, the less the excitation. This lateral interaction is approximated in the SON with a step function. All nodes in the immediate neighborhood of the winning node participate in the learning process. The Mexican Hat function could be modeled more precisely by allowing the neighborhood nodes to participate at varying degrees, but the computationally simpler step function performs just as well.
The neighborhood is determined by choosing all nodes within a specified number of rows and columns from the winning node. As shown in Figure 3, if the neighborhood size is two, then all nodes two or fewer rows and columns away are part of the neighborhood. More elaborate schemes for determining the neighborhood exist, such as using a circular region around the winning node. However, implementing the rectangular neighborhood is easy and works well.
A node participating in the learning process updates its weight vector by making it more closely resemble the input vector:
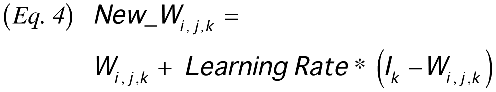
where i and j are the row and column, and k is the vector component ID.
The Update_Weight_Vectors function first finds the range of nodes in the winning node's neighborhood. If the range goes out of the Kohonen layer's bounds, it is cropped. (Some implementations may allow the neighborhood to wrap around to the other side of the Kohonen layer.) The weight vectors in the neighborhood are then adjusted.
void
Update_Weight_Vectors
(double pattern[],
double W[MAX_ROWS][MAX_COLS]
[MAX_INPUT_NODES],
int num_input_nodes, int rows,
int cols,
int winning_row, int winning_col,
double learning_rate,
int neighborhood)
{
int i,j,k;
int row_start, row_stop, col_start,
col_stop;
// Find range of neighborhood
row_start=winning_row-neighborhood;
row_stop=winning_row+neighborhood;
col_start=winning_col-neighborhood;
col_stop=winning_col+neighborhood;
// Correct range if out of bounds
if (row_start<0) row_start=0;
if (row_stop>=rows) row_stop=rows-1;
if (col_start<0) col_start=0;
if (col_stop>=cols) col_stop=cols-1;
// Update all weights in neighborhood
for (i=row_start; i<=row_stop; i++)
for(j=col_start; j<=col_stop; j++)
for (k=0;k<num_input_nodes;k++)
W[i][j][k]+=learning_rate*
(pattern[k]-W[i][j][k]);
}
The neighborhood size is initialized to a value around half the number of rows or columns in the Kohonen Layer. As training progresses, the neighborhood size periodically decreases. Also, the learning rate (the amount each link value can be modified) continuously decreases during training, beginning between 0.5 and 1.0 and decreasing to 0.01 or less. Training stops after the training set has been presented to the network a predetermined number of times. The SON is more forgiving than the BP network when it comes to network size and training parameters. Nevertheless, you will probably need to try several variations before attaining the results you desire.
The code segment below performs the training process. The weight vectors are initialized, and the training set is presented num_iterations times. For each iteration of the training set, the learning rate is computed, and the neighborhood size is adjusted (if necessary). For each pattern in the training set, a winning node in the Kohonen layer is found, and the weight vectors in its neighborhood are updated.
Initialize_Weights(W,rows,cols,
num_input_nodes);
// Initialize Weight vectors
// Initialize neighborhood size
neighborhood=initial_neighborhood;
// Training Loop
while (iteration<num_iterations)
{
// Calculate learning rate
learning_rate =
initial_learning_rate -
(((double)iteration/
(double)num_iterations) *
(initial_learning_rate -
final_learning_rate));
// Decrement neighborhood size if necessary
if ((iteration+1)%
neighborhood_decrement == 0 &&
neighborhood > 0)
neighborhood--;
if (iteration%500==0) // Print status and
// store weights
{
// Print status
printf("%ld. Learning Rate: %lf"
"Neighborhood: %d\n",
iteration,learning_rate,
neighborhood);
// Store feature map
Save_Weights("outfile.dta",W,
rows,cols,
num_input_nodes);
}
// Present each training pattern to network
for (id=0; id<num_patterns; id++)
{
// Find Winning Kohonen layer
// node for input pattern
Get_Winning_Node(pattern[id], W,
num_input_nodes, rows,
cols, &winning_row,
&winning_col );
// Update all Kohonen node weight
// vectors in winner's neighborhood
Update_Weight_Vectors(
pattern[id], W, num_input_nodes,
rows, cols, winning_row,
winning_col, learning_rate,
neighborhood);
}
iteration++; // Increment current iteration
}
// Store feature map
Save_Weights("outfile.dta",W,rows,cols,
num_input_nodes);
Using the SON
Now that you know how to train a SON with a set of input patterns, what does this accomplish? The SON will organize the input patterns into clusters (one cluster for each node in the Kohonen layer), and more importantly, the clusters will be arranged in the Kohonen layer so that similar clusters will be near one another. (This behavior is characteristic of a Topological Conserving Feature Map, or TCFM.) The beauty of the SON is that you do not need to know anything about the relationships between the input patterns for the SON to find the clusters and maintain their topology.
I present two examples to illustrate what the SON is learning during the training process. The same training set will be used for both examples; it is composed of 1,000 two-dimensional points randomly distributed in a plus (+) shape (shown in Figure 4). The training set component values also are scaled to fit in the range of 0.0 to 1.0. While this training set is trivial, it will clearly illustrate what the SON is learning and how the resulting weight vectors (or feature map as it is sometimes called) can be used. This training set contains only two components for each input pattern, meaning that there are two link values for each Kohonen-layer node. Since there are only two link values per Kohonen-layer node, it is very easy to plot a point in two-dimensional space for each node and monitor the progress of the network during the training process (shown in Figures 4 and 5). The SON is certainly not limited to input patterns with two components, but it is easier to illustrate and visualize with data that is not dimensionally complex.
The first example uses a SON with an input layer containing two nodes (one for the x and y coordinates of the input patterns) and a Kohonen layer containing 100 rows and 1 column. The neighborhood size is initialized to 40, decreasing by 1 every 125 iterations of the training set. Initialized to 0.5, the learning rate continuously decreases to 0.01. The training set is presented to the network 5,000 times, and the weight vectors are stored every 500 iterations to create the feature map movie shown in Figure 4. Each movie frame plots a point for each Kohonen-layer node (using its link values as the coordinates) and draws a line between the points of each neighboring Kohonen-layer node. Since the Kohonen layer in this example contains only 1 column, the feature map resembles a string strung through the Kohonen-layer nodes. It is very interesting to see the string approximate the input patterns as training progresses. Before training begins, the random link values are just a jumble of lines. After only 500 iterations of the training set, a coherent line appears and slowly winds through the plus shape of the training set data. After 3,500 iterations, the plus outline begins to appear. At 5,000 iterations, the string weaves through the plus shape. Remember that the Kohonen layer contains only 100 nodes, so the "string" has only 100 vertices. Since there are 1,000 points in the training set, the SON must wind the string through the training set as best as it can.
The second example uses a differently shaped Kohonen layer containing 10 rows and 10 columns. The neighborhood size is initialized to 5, decreasing by 1 every 1,000 iterations of the training set. Again, the learning rate, which is initialized to 0.5, continuously decreases to 0.01. The training set is presented to the network 5,000 times, and the weight vectors are stored every 500 iterations to create the feature map movie shown in Figure 5. In this example, each Kohonen-layer node has a neighboring node to its left and right, as well as above and below. So, as lines are drawn between neighboring Kohonen-layer node points, a net is created instead of a string. Before training begins, the random link values create a jumble; however, the plus shape becomes recognizable after only 2,000 iterations of the training set. The net continues to better approximate the plus shape as training continues. Again, the Kohonen Layer contains only 100 nodes (10 rows by 10 columns), so the net has only 100 vertices. The Kohonen-layer nodes approximate the training set very well (hindered only by the rounding of the plus's corners).
Even in this trivial example, the SON has determined a set of categories (clusters) for the training patterns and has organized these categories in a topological fashion; similar categories are next to one another as seen by the creation of the string and the net in the previous examples. This feat alone is pretty amazing considering that the training set was just a set of random points.
The SON can also be used as a classifier. Once the SON is trained, you can use the Get_Winning_Node function to find the position of the Kohonen-layer node value whose weight vector is closest to a new pattern's input vector. The position of the winning node (row, column) identifies a category, and similar patterns will have the same winning node.
Still don't know what this is good for? While TCFMs are neat to look at, what value do they really provide? The value of what the SON learned is sometimes subtle and not immediately obvious. The key word here is "learned." In the previous examples, the data set is a trivial set of two-dimensional points. You can easily visualize how these points could be organized into groups. (This is precisely why this data set was used in the example.) Still, the ability to organize seemingly random data (even data this simple) is not such a trivial task. Categorizing data is a simple task for a human, but it is often hard to do algorithmically without the aid of some AI tool. How could you accomplish the same results (running a string through or draping a net over a set of random points) with another algorithm on this simple data set? If you get this far, then increase the dimensionality of the data.
Now, think about applications that can collect a lot of data. For example, you are running a website (a portal) that provides various types of information such as news, sports, stock quotes, horoscopes, shopping, etc. Your website's goal is to sell advertisements (in the form of banners), and you get paid based on how many of your guests visit the advertised websites. Increasing the likelihood of your guests visiting the advertised spot greatly depends on how interested they are in the displayed advertisement. So, how can you help determine the best advertisement to display? Make a training set out of your web server's log files, making vectors out of the possible pages your site offers. (This could be a lot of components or it could just be the major pages.) You create a training vector for each individual user, and the components' values could be how many times a user visits a particular page. Normalize the vectors, train the SON, and you will get a TCFM that groups your users according to web pages they have visited. You must still associate some advertising scheme with each group of users, using other data from your web server's log files (such as the site the users came from, the type of site the users visited after yours, a purchase made, etc.). The SON can be set up to continuously learn and adjust to the varying trends of your users.
Conclusion
This article has merely scratched the surface of SONs. A variety of implementation techniques and variations of the architecture and training methods exist. Nevertheless, the SON offers power when dealing with little-known data or not-so-obvious groups within a set of data. This article provides the basic tools to create your own SON. (Full source code is available on the ftp site — see p. 3 for downloading instructions.) Also, you can find many good references on SON theory, designs, and applications (see suggested readings below). The SON certainly does not replace the BP neural network or any other network architecture. However, it is another tool from the AI toolbox to make you more a productive and capable programmer.
Suggested Readings
Robert Hecht-Nielsen. Neurocomputing (Addison-Wesley, 1990).
James A. Freeman and David M. Skapura. Neural Networks: Algorithms, Applications, and Programming Techniques (Addison-Wesley, 1991).
T. Kohonen. Self-Organization and Associative Memory (Springer-Verlag, 1984).
T. Kohonen. "The 'Neural' Phonetic Typewriter." Computer (March 1988).
H. Ritter, T. Martinetz, and K. Schulten. Neural Computation and Self-Organizing Maps (Addison-Wesley, 1992).
Dwayne Phillips. "The Backpropagation Neural Network," C/C++ Users Journal, January 1996.
Maureen Caudill and Charles Butler. Understanding Neural Networks: Volumes 2 (MIT Press, 1994).
Joey Rogers is an application developer for Intergraph Corporation in Huntsville, Alabama. He is also the author of Object-Oriented Neural Networks in C++. He can be reached at srogers@hq.pcmail.ingr.com.