After 16 years as an experimental physicist, five as a computer design engineer, and six as a professional programmer, Martin Scolnick can be found managing the engineering group at Z-World Engineering, in Davis, CA 95616, 916-757-3793 or Compuserve 76662,3406.
Many discrete probability functions, such as those associated with flipping a coin or rolling dice, can be modeled by a single process: picking balls from a set of urns. If each urn contains black and white balls, the odds of picking one of the two colors will depend on the ratio of black to white. For example, with a ratio of 2:1, you would expect to pick black balls twice as frequently as white ones, as long as you replaced the ball after each pick to maintain the ratio.
Most computer languages include a pseudo-random number generator function, such as random(n), which returns a random integer in the range 0 to n-1. Since all of the numbers in this range are equally likely to occur, the distribution is called "uniform." You can use uniformly distributed random integers in the "picking from an urn" process to generate the same probability function as flipping a coin:
1. Place one black and one white ball in each of two urns.
2. Use a random number generator to obtain a 0 or 1.
3. If the generator returns a 0, pick at random (i.e. blindfolded) a ball from the urn labeled "head"; otherwise, pick a ball from the urn labeled "tail." In either case, return the ball to its respective urn.
4. If the ball is black accept the result, head or tail; otherwise return to step 2.
This process may seem unnecessarily complex, considering that you could use random(2) to directly produce a 0 or a 1 with the equal probabilities that are required to simulate a normal coin flip. However, the advantage of the urn paradigm becomes apparent when you simulate a "loaded" coin by changing the ratio of black to white balls in either of the two urns.
To simulate the rolling of a die, increase the number of urns to six and obtain a random number in the range 0 to 5 from the random number generator. To simulate a loaded die, change the ratio of black to white balls from 1:1 to something else in one or more of the urns.
To generalize the algorithm to an arbitrary discrete probability function of n events, use n urns in step 1 and load them with black and white balls in whatever ratio the function requires. In step 2, generate an integer in the range 0 to n-1 and use it to select an urn from which a ball is picked at random. If it's black, accept the random number generator's output as an "event;" otherwise, return to step 2.
An Example Implementation
SumNPicks
The function SumNPicks (Listing 1) will return "events" at the statistical frequency implied by any of a wide range of "pick from an urn" models. A specific model is selected by specifications in the first three fields of a RAND structure (Listing 2) .The number of distinct objects, nobjs, refers to the two sides of a coin, or the six faces of a die, or the number of intervals in the domain partition of the normal distribution, depending on which model (probability function) is selected. The number of random picks, npick, refers to the number of flips or the number of dice, etc. When npick is 1, the number of distinct events, nbin, will be the same as the number of distinct objects. When npick > 1, nbin will equal the number of summing events that are possible when the objects are picked npick times (e.g., for two dice: nobjs = 6; npick = 2; nbin = 11). The label nbin refers to the number of bins (intervals) that are used for displaying statistical event data in a histogram. While many other kinds of events can be constructed from several picks, the present program is limited to events that can be generated by summing the results of picking objects and replacing them.
To simplify some of the display routines, events are treated as indices. This implementation limits the field of events to positive integers and uses the ordinal value of an event to find the label that describes it. For example, in one simulation, index = 0, could mean the event was a "Head," but in another simulation it might mean that a dart hit the target at a point in the zeroth interval from the bullseye. The demonstration program finds the appropriate label by using the event as an index into the array selected by the pointer in the last field of the RAND structure. As a conceptual aid for distinguishing between these two uses of integers, as cardinal numbers and as event indices, the type index is defined in Listing 2.
In simulations where the model requires units of length or voltage, generating labels from the indices returned by SumNPicks requires additional code. In Listing 6, for example, an extra statement adds a random noise value to the input signal in AddNoise; in RandWalk (Listing 8) x and y are assigned lengths. Note that these statements apply scaling factors as well as offsets (viz. "(nbin-1)" is an offset that determines which index corresponds to 0 units), so index = 0 can mean "-0.1 volts," and index = 6 can mean a random walk displacement of "0 microns."
The Demonstration Program
The driver in Listing 3 and Listing 4 excercises three sample applications: a module which displays histograms, a module which simulates a random walk, and a module which simulates the effect of various filters on a "noisy" electronic signal. Each application module is invoked with each of the probability distribution models specified in the tbl array of RAND structures (initialized in Listing 3) . On each pass through the main loop, the driver copies one of these RAND structures into a local buffer, xampl. The demonstration program includes specifications for distributions that correspond to:
- a single coin toss
- a single loaded coin toss
- two coins tossed
- one die thrown
- two dice thrown
- two loaded dice thrown
- four dice thrown
- the normal distribution
- a uniform circular distribution
The Histogram Module
MakeHistogram (Listing 5 and Listing 6) uses the model specifications in xampl to generate simulated statistical data, and displays the associated frequency histogram.Note how many flips of an "honest" coin are required before the heads:tails ratio gets close to 50:50, and how long it takes for the normal distribution to shape up. The distribution shown in Figure 1, for example, represents over 5,000 trials. In the case of the loaded coin, heads are twice as likely to occur as tails, so the large-number statistics are expected to show 66.67 percent heads and 33.33 percent tails. In the loaded dice case, the 1 (index = 0) is twice as likely to occur as any of the other five numbers. The histogram for two loaded dice, therefore, shows a bias for all sums less than 8 (as can be seen in Figure 2) because these rely on combinations that include pairs with 1, whereas sums of 8 or larger rely entirely on pairs that exclude 1.
Random Walk
This exercise (Listing 7 and Listing 8) demonstrates the use of computer generated random variables in simulating phenomenon such as Brownian motion, molecular dispersion, and diffusion. Here, the selected probability function is used two times, once to determine the x-component of a step and a second time for the y-component. (The simulation which uses the uniform circular probability model calls the probabiltity model only once, since the step length is fixed.) When the path intercepts a boundary, the simulation stops and displays the number of steps. Because steps of one pixel would obscure the geometric structure of the paths, RandWalk amplifies the steps by the scaling factor, sf.
When the coin flip model is used, each step component has only two options, 1 unit, so the "walk" is constrained to diagonal paths, as shown in Figure 3.
This also means that each step has the same length, namely 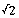 units. On the other hand, when two dice are used, each step component has 11 possibilities, five different lengths in either the positive or negative direction and the possibility of a zero step, where no movement occurs.
units. On the other hand, when two dice are used, each step component has 11 possibilities, five different lengths in either the positive or negative direction and the possibility of a zero step, where no movement occurs.
Of the sample probability models, the last one, "uniform circular," is probably most appropriate to a simulation of molecular dispersion. In this case (Figure 4) 2p radians have been divided into 24 equal angles and the probability for picking any one of them is uniform. The fact that the size of each step is a constant may be acceptable if we equate it to the mean free path of a molecule in a gas. In any case, the choice of probability function depends on the objective of the simulation.
The loaded coin model generates statistics that obey the binomial law. That is, if the coin is loaded for heads and if a head means a step toward a border, we can define such a step as a "success" in a "repeated Bernoulli trial." In this case, the binomial law gives the probability for obtaining k successes and n-k failures after n tries. Since the mean for this distribution is np, where p is the probability for success and 1-p is the probability for failure, the expected number of steps to wander from the origin to a border, D steps away, is n = D/(2p-1). In this program, each step in the loaded coin model has been scaled to 11 pixels and the origin has been placed in the center of a 400 x 400 pixel window, so D = 200/11 = 18 steps. As noted earlier, p = 0.667, so we should expect a "molecule" to reach a border after n = 54 steps, on average. To verify this result as a reasonable estimate, run the program, say ten times, and compute the average of the number of steps that it took for the "molecule" to reach a border (a total "verification" would require an infinite number of samples). Note also that, because the coin is biased for "heads," the path almost always intercepts a border in the top left quadrant.
Electronic Filters
MakeScopeSignals (Listing 5 and Listing 6) simulates the appearance of a noisy square wave on an oscilloscope screen and demonstrates the effects of three different digital filters on noise. The results in Figure 5 and Figure 6 show how different distributions can simulate different types of noise. The noise component of the "noisy signal" in Figure 5 is generated using a normal distribution. Since the domain of this distribution is arbitrarily partitioned into 25 intervals, there are 13 different amplitudes of noise (positive, negative and zero), with zero being the most likely. The noise in Figure 6, on the other hand, was generated by the single coin flip algorithm, so it has only two possibilities; it adds either a positive or a negative increment of constant magnitude to the signal.The square wave (the "signal") is a digitized representation of a continuous voltage wave form; it's a series of numbers that represents samples of a signal taken per unit time. The algorithms for generating random numbers are the same as in the random walk, except that instead of summing them to get a net distance from a fixed point, one random number is added to each number in the series to simulate noise.
The Filters
In both cases, the resulting "noisy signal" is then processed by three filters: a "running average" filter, a simulated RC filter, and a differentiator. All three filters are implemented as weighted average computations.In general, a "weighted average" filter replaces the ith number in a series with the sum of the weighted values of itself and its neighbors. For example, we could replace the third number in the series, 8, 10, 9, with
(8*W1+10*W2+9*W3) / (W1+W2+W3)where the W's are referred to as "weights." When W1=W2=W3, the filter just replaces 10 with the average of 8, 10, 9.
If each number in a series is replaced with the average of itself and n of its neighbors (a "running average" filter), some of the high frequency noise will be smoothed out, especially if the average value of the noise is 0 and n is large. However, if n is too large, some of the useful signal components will also be lost. Using a geometric series for the values of the weights, simulates the effect of a "low-pass RC" filter of the kind that might be found in the bass control of a radio. The differentiator is an interesting hybrid of high-pass and low-pass filter; in effect, it differentiates data that have been smoothed by a running average filter. As the number of weights is reduced, however, it begins to perform more like a high (frequency) pass filter.
The Filter routine is responsible for the convolution of data and weights. This single routine simulates all three filters, by applying the weighting schemes from the filtr_wts array (initialized in Listing 3) . The first two numbers in each of the filtr_wts arrays are the number of weights and the sum of the weights, respectively; the remaining numbers are the weights themselves. Pointers to this table, to a series of noisy data, and to a space for storing filtered data are passed to Filter in Listing 6.
The first filter array results in a running average. Note (in Figure 5 and Figure 6) how a noisy square wave is transformed to a less noisy but somewhat trapezoidal wave form by this filter. By increasing the number of weights, the square wave will get smoother, but its slopes will become less steep.
The second array represents a low-pass RC filter, as indicated by the geometric progression. This filter tends to round off the leading edge of a square wave and causes the trailing edge to decay exponentially. Increasing the number of weights will result in smoother data, but will increase the distortion at the leading and trailing edges.
The third array represents a differentiator. In this filter, the first six weights are negative and the last six are positive. This sharp polar division is characteristic of differentiators. Because the center weight is zero and the magnitudes of the neighbors are symmetrically distributed (constant, in this case), when applied to a series of constant numbers, this filter will produce a constant zero output — exactly what we want from a differentiator.
Conclusion
The uniform output of the C function, random(n), can be "shaped" into random integers with prescribed frequency distributions that have many applications. Clearly, this program can be expanded in a number of ways. For use as a statistics teaching aid, a variety of probability functions and RAND records can be added to the existing code and iterative loops can be used to compute the means and variances, etc. of simulated samples. The additional distributions would probably require a menu driven program. For use as an engineering tool, the RAND tables, the filter weight arrays, and real or simulated input data can be read from external files to test filter designs. If the program is modified to accept noise amplitude as a command line argument or as a menu option, users can control both the nature of the noise and the signal-to-noise ratio in their analysis. If the filtered data are also written to external files, they can be processed many times by the same or different filters. More elaborate versions of this program can be used in more complex programs. For example, radiation shielding requirements can be estimated by simulating the high energy particle scattering that results in a nuclear beam experiment.