William Smith is the engineering manager at Montana Software, a software development company specializing in custom applications for MS-DOS and Windows. You may contact him by mail at P.O. Box 663, Bozeman, MT 59771-0663.
C as a Number Crunching Language
The scientific community has long considered FORTRAN a language better suited to numerical applications then C. A common belief is that C is a low-level language for systems programming and FORTRAN is for number crunching. Even fine books such as Numerical Recipes in C help perpetuate this notion. If used properly, I believe C is a better number crunching language than FORTRAN. Because of its flexibility and low-level language features C can be optimized beyond FORTRAN.In this article I am going to point out some of the features of C that can produce faster algorithms. To illustrate, I will analyze the tasks of inverting a matrix and solving a set of simultaneous equations. These tasks are required operations for many numerically-intensive applications. I will present two versions of the Gauss-Jordan numerical method for solving a system of equations and inverting a matrix. The first is a FORTRAN-like algorithm in C the second is a version that utilizes features unique to C.
Advantages of C Over FORTRAN
Besides floating-point operations, addressing and moving large amounts of data are operations that take up processing time in numerical applications. To increase code performance, the programmer must improve the speed of floating-point operations, decrease the overall number of operations and make the data addressing more efficient. Not much can be done to improve upon the speed of the floating-point operations. It is highly dependant upon the math library and hardware. What you can easily improve upon are the methods of addressing and the number of operations in a particular algorithm.One of the features of C that differentiates it from FORTRAN is the pointer type and the resulting direct access to memory. In C, you can address memory with a closeness and power that does not exist in FORTRAN. You can also use direct memory access to speed up your numerical routines. Numerical applications that process large arrays and matrices of floating-point numbers can benefit greatly by improvements in addressing and operation reduction through the use of pointers. In C, by using pointers, you can exchange two rows of a matrix with a single swap operation. In FORTRAN, you are forced to use a swap operation for each element in the row. Ironically much of the C code that was inspired or translated from FORTRAN inherits this inefficiency. But all it takes is some minor changes and use of pointers to speed up this code.
Gauss-Jordan as an Example
The Gauss-Jordan elimination method of inverting a matrix and solving a set of simultaneous equations is a popular and well-known methodology in numerical analysis. Gauss-Jordan is a variation of the simpler Gaussian elimination algorithm. Gauss-Jordan both inverts a matrix and solves a set of linear equations.For example, the following set of three linear equations in three unknowns
6x + -4y + 6z = -4 4x + 5y + -2z = 10 -6x + 2y + -5z = 3becomes
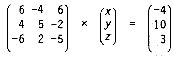
in matrix notation. You can further simplify the expression to [A][X] = [B]. The first matrix, [A], is the coefficient matrix. The solution vector, [X] and the constant vector, [B], follow in the expression. For the above example the solution vector [X] is
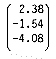
and the inverse of [A] is
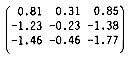
Gauss-Jordan is not the best choice of numerical methods if one is only interested in solving a set of linear equations and not interested in obtaining the inverse of a matrix. Neither is it the best choice for inverting matrices if the matrix is sparse or conforms to certain classes of matrices. Nevertheless, Gauss-Jordan is popular and will serve as an excellent example for the points I wish to make.
The optimization techniques I present here utilize more efficient ways to address and access matrices. You can apply these techniques to other numerical methods not just Gauss-Jordan. I use a variant of the Gauss-Jordan algorithm that employs partial pivoting. Partial pivoting is the process of exchanging rows in the matrix. Without it, the reduction method is prone to round-off error and divide-by-zero singularities. Full pivoting involves the exchange of columns in addition to the exchange of rows. Full pivoting is slightly more stable, but is more complicated and potentially slower. The pivoting process is the operation that benefits the most from addressing optimization. Nearly all matrix-inversion and simultaneous-equation solution algorithms utilize pivoting and can benefit from addressing optimization.
Matrices in C
To employ pointer-addressing optimization, matrices must be set up in a specific way. To accomplish this, I have created a new type, matrix_t, and the corresponding constructor and destructor functions for this type. Listing 1, MATRIX_T.C, contains the code for the functions to create and destroy matrices of type matrix_t. Listing 2 contains the associated include file, MATRIX_T.H, for MATRIX_T.C. I define the matrix type, matrix_t, in MATRIX_T.H.In FORTRAN array indices begin at 1. In C, array indices begin at 0. I have seen this difference handled in three different ways when translating FORTRAN code to C. One is to dimension the arrays and matrices an extra element larger. Since this method never uses the 0 array element, this method wastes space. Another method is to change the loop indices to start at 0 and go to the array size minus 1. A third way is to shift the starting array index to 1 by decrementing the pointer that is set to the array name. This last method requires a bit of extra bookkeeping. I choose to let array indexing begin at 0 and to change the loop indices.
Multiple Block Matrices
The function cr_matrix in Listing 1, allocates the memory for a matrix on the heap and sets it up so you can use array ([]) notation to access elements in the matrix. You use the expression, A[i][j], to access the element at the ith row and jth column of matrix A. cr_matrix first allocates memory for the pointers to the rows of the matrix. It then allocates memory for each row individually and assigns a row pointer to this memory. I use the function calloc to allocate the memory because it will also initialize all the memory to 0. cr_matrix calls the function calloc once for every row and once for the row pointers. This results in the allocation of many separate blocks of memory. The number of blocks is equal to the number or rows plus one. This has advantages and disadvantages over allocating a single block of memory. The disadvantages are that it is slower and more complicated; and requires more memory overhead, a special destructor function, and may later fragment memory. The only advantage is that it works well with the segmented architecture of the Intel processors under MS-DOS. When using the large or compact memory models that employ far pointers, you can create matrices that total larger than a single 64KB segment of memory.
Single Block Matrices
For situations of abundant memory or if you are using near pointers with the small or medium memory models, I suggest you use the function cr_matrix_s, shown in Listing 1. This function creates a matrix on the heap with a single call to calloc. The way cr_matrix_s accomplishes this, is to allocate enough memory in a single block to hold both the pointers to rows and all the rows. The pointers to rows are then set equal to the address of where each of the rows begin in the block. You can destroy a matrix created with cr_matrix_s with a single call to free. I have included a destructor function, fr_matrix_s, in MATRIX_T.C, shown in Listing 1, for completeness. All it does is make a call free. fr_matrix_s is an ideal candidate for replacement with a macro.
Gauss-Jordan FORTRAN Style
GS_JRD_F.C, shown in Listing 3, contains a version of the Gauss-Jordan function, gauss_jordan, that will look familiar to anyone that has coded or seen the Gauss-Jordan function coded in FORTRAN. (Listing 5 contains the associated include file. It can be used in both the FORTRAN-style code or the C-style code.) It is also indicative of what you will see in much of the published numerical C code. The function takes a matrix of the equation coefficients and a matrix of the constant vectors as parameters. gauss_jordan also requires the number of rows and the number of constant vectors as parameters. There is not a single pointer dereference operator (*) or address of operator (&) in the entire function. This is FORTRAN-style C. Code blindly translated from FORTRAN to C looks like this. It is straight forward, easy to understand, and logical. But it is not as efficient as it can be.
Gauss-Jordan C Style
GS_JRD_C.C, shown in Listing 4 (and the associated include file in Listing 5) , contains a version of function gauss_jordan that takes advantages of the features of C. Overall it is not that different than the FORTRAN-style version of Listing 3. Upon closer examination, the differences become apparent. I wrote the code so the two different implementations are line for line comparable. What are the differences? I use variables to store temporary values to limit the level of indirection when evaluating an expression with array notation inside loops. This is no big deal. Some compilers with advanced and aggressive optimization may do this for you. Unfortunately, you can not count on it. What else is different? The section of code that swaps the elements between two rows is different. The FORTRAN-style version of gauss_jordan employs a loop through all the columns of a row and swaps each row element. The C-style version eliminates this loop and swaps pointers to the rows. This swapping must be done for both the matrix of the coefficients and the matrix of the constant vectors. This difference can eliminate many operations. This is especially true for large coefficient or constant-vector matrices.
Using gauss_jordan
The following code fragment illustrates the sequence of how to use the gauss_jordan function. You first make a call to cr_matrix to create the space for the coefficient and constant-vector matrices. Then you load the matrices with data. Where the data comes from and what is done with the results of the matrix inversion and equation solution is application specific. For this reason, I have not included a demonstration program. Once the matrices are loaded with values, your program can make a call to gauss_jordan. gauss_jordan replaces the coefficient matrix with its inverse and the constant vector matrix with solution vectors. You can then process the results. When you are finished with the results, you destroy the matrices by calls to fr_matrix.
.
.
.
matrix_t A, B;
/* Create space for matrix */
A = cr_matrix( NumRow, NumRow );
B = cr_matrix( NumRow, NumVec );
/* Load matrix here */
/* Calculated inverse
** and solve system */
status = gauss_jordan(
A, NumRow,
B, NumVec );
/* Process the results */
/* Destroy matrix */
fr_matrix( A, NumRow );
fr_matrix( B, NumRow );
.
.
.
C versus FORTRAN Style
So what are the advantages and disadvantages of the C-style code to the FORTRAN-style code? Depending on how far you take the optimization, the readability of the C-style code may suffer. The C-style code in Listing 4 is still quite readable. Proper choice of variable names helps in this regard. The difference in compiled size is not very significant. Under Microsoft C v6.0 with full optimization, the object code size for the FORTRAN-style version was 1038 bytes. The C-style was 962 bytes. The savings in size are small. Possibly this may be important for an embedded application.Although the size difference is not very significant, the speed advantage of the C style over the FORTRAN style is significant. This is especially true as the matrix size increases. I tested three different matrix sizes. For each case, I only used a single-column constant vector. If solving for more than one constant vector at a time, the differences would be greater.
Table 1 shows the ratio of the C-style time to the FORTRAN-style time. I used Borland's Turbo Profiler to measure how much time was spent in the gauss_jordan function. I generate the ratios by dividing the amount of time spent in the C-style code by the amount of time spent in the FORTRAN-style code. This normalizes the time spent in the FORTRAN code to 1. The smaller the number the faster the C-style code as compared to the FORTRAN-style code. I use the ratios here since actual times are very hardware dependant and lose meaning from one system to another. It is clear that the speed advantage of the C-style code increases as the matrix size increases. In fact, for the three points tested, the ratio decreases linearly with the matrix row size. I doubt it remains linear for long, but probably approaches the value of zero asymptotically for large matrices. I would expect the C style to be twice as fast as the FORTRAN style for a 20 x 20 matrix and an order of magnitude (10 times faster or taking 0.1 of the time) faster for a 100 x 100 matrix. I ran the tests on a 25MHz 80486 computer. The ratios may be different on a system without a math co-processor.
Other Optimization
The optimization to the C-style version of gauss_jordan in Listing 4 are by no means complete. A goal I kept in mind when writing the C-style version was to keep the overall algorithm the same and maintain clarity. I was tempted to totally replace the array notation with pointer notation and pointer incrementing. You may gain some additional time savings from this. You can even replace the for loops with while loops and increment pointers. I avoided these optimizations because I have found that the savings are small especially with an optimizing compiler. Besides the code starts to diverge significantly in style. The algorithm is hard to follow and to compare directly with the FORTRAN-style code if it changes too much.Another possible optimization, that became apparent, does not depend on features unique to C. When using the profiler on the code I discovered that the fabs function was taking up nearly as much time as the rest of the gauss_jordan function. By creating a temporary place holder for both fabs ( Pivot ) and the sign of Pivot, the number of times gauss_jordan calls fabs can be reduced. By decreasing the amount of time spent in floating-point operations, the time savings due to addressing improvement and operation reduction becomes even more significant. This optimization will tend to further decrease the ratios in Table 1.
Conclusions
No computer is fast enough. This truism becomes all to apparent when waiting hours for your computer to calculate a 1,000 node finite element model of a real physical system. Speed becomes important when doing scientific modeling, finite element analysis and any application that must process a large amount of data. Even though the speed of hardware is constantly improving, you can realize significant speed advantages by attention to detail when writing code. By taking advantage of some of the features of C, you can also significantly improve the performance of existing numerical code in C that was translated from FORTRAN.