P.J. Plauger is senior editor of The C Users Journal. He is secretary of the ANSI C standards committee, X3J11, and convenor of the ISO C standards committee, WG14. His latest book is Standard C, which he co-authored with Jim Brodie. You can reach him at pjp@plauger.uunet.
Introduction
Writing good math function is hard. It is still commonplace to find professional implementations of programming languages that provide math functions with serious flaws. They may generate intermediate overflows for arguments with well-defined function values. They may lose considerable significance. Or they may generate results that are just plain wrong in certain cases.What's mildly surprising about this state of affairs is that implementors have had plenty of time to learn how to do things right. The earliest use for computers was to solve problems with a distinctive engineering or mathematical slant. The first libraries, in fact, consisted almost entirely of functions that computed the common math functions. FORTRAN, a child of the 1950s, was named for its ability to simplify FORmula TRANslation. Those formulas were larded with math functions.
Over the years, implementors have become more sophisticated. The IEEE 754 Standard for floating-point is a significant milestone on the road to safer and more consistent floating-point arithmetic. (I discussed floating-point representations and the IEEE 754 Standard in Standard C, CUJ January 1991.) Yet in another sense, IEEE 754 adds to the implementor's woes. It introduces the complexity of gradual underflow, codes for infinities and not-a-numbers, and exponents of different sizes for different precisions. Small wonder that many implementors often support only parts of the IEEE 754 Standard.
Regular readers of this column know by now that I have written an entire implementation of the Standard C library. I have been discussing it in installments for nearly a year now. You can soon see it all in one place. Prentice-Hall is publishing my book, The Standard C Library, and The C Users Group is making the machine-readable code available.
I spent about as much time writing and debugging the functions declared in <math. h> as I did the rest of the library combined. That surprised me, I confess. I have written math libraries at least three times over the past twenty-odd years. You'd think that I have had plenty of time to learn how to do things right, as well. I certainly thought so.
Goals
Writing <math. h> took so long because I adopted several rather ambitious goals:
- The math library should be portable over a range of popular computer architectures. All functions are designed to yield 56 bits of precision. That makes them suitable for a number of machines with 64-bit double representation — those with IEEE 754-compatible math co-processors (53 bits of precision), the IBM System/370 family (53 to 56 bits), and the DEC VAX family (56 bits).
- Each function should accept all argument values in its domain (the argument values for which it is mathematically defined). It should report a domain error for all other arguments. In this case, the function returns a special code that represents NaN for not-a-number.
- Each function should produce a finite result if its value has a finite representation. It should report a range error for all values too large or too small to represent. If the value is too large in magnitude, the function returns a special code +Inf that represents plus infinity, or the negative of that code -Inf that represents minus infinity, as appropriate. If the value is too small in magnitude, the function returns zero.
- Each function should produce the most sensible result for the argument values NaN, +Inf, and --Inf. On an implementation that supports multiple NaN codes, such as IEEE 754, the functions preserve particular NaN codes wherever possible. If a function has a single argument and the value of that argument is a NaN, for example, the function returns the value of the argument.
- Each function should endeavor to produce a result whose precision is within two bits of the best-available approximation to any representable result.
- No function should ever generate an overflow, underflow, or zero divide, regardless of its argument values and regardless of the result.
- No function requires a floating-point representation other than double to perform intermediate calculations.
Non-Goals
I should also point out a number of goals I chose not to achieve:
- The library doesn't try to distinguish +0 from --0. IEEE 754 worries quite a bit about this distinction. All the architectures I mentioned above can represent both flavors of zero. But I have trouble accepting (or even understanding) the rationale for this extra complexity. I can sympathize with recent critiques of the IEEE 754 Standard that challenge that rationale. Most of all, I found the functions quite hard enough to write without fretting about the sign of nothing.
- The library does nothing with various flavors of NaNs. IEEE 754 arithmetic, for example, distinguishes quiet NaNs from signalling NaNs. The latter should generate a signal or raise an exception. This implementation essentially treats all NaNs as quiet NaNs.
- I provide low-level primitives only for the IEEE 754 representation. They happen to work rather well with the DEC VAX floating-point representation as well, but the fit isn't perfect. The VAX hardware doesn't recognize as special the code values for things like +Inf and -Inf. Such codes can disappear in expressions that perform arithmetic with them. The primitives must be altered to support System/370 floating-point.
- I have not checked the functions on System/370. The "wobbling precision" on that architecture requires special handling. Mostly, I have tried to provide such special handling, but it may not be thorough enough.
- Many functions are probably suboptimal for machines that retain much fewer than 53 bits of precision in type double. The C Standard permits a double to retain as few as ten decimal digits of precision — about 31 bits. For such machines, you should reconsider the approximations chosen in various math functions.
- Functions that use approximations will almost certainly fail for machines that retain more than 56 bits of precision. For such machines, you must reconsider the approximations chosen.
- Floating-point representations with bases other than 2 or 16 are poorly supported by this implementation of the math library. An implementation with base-10 floating-point arithmetic, for example, would call for significant redesign.
Numerical Techniques
Computing math functions safely and accurately requires a peculiar style of programming:
- The finite precision of floating-point representation is both a blessing and a curse. It lets you choose approximations of limited accuracy. But it offers only limited accuracy for intermediate calculations that may need more.
- The finite range of floating-point representation is also both a blessing and a curse. It lets you choose safe data types to represent arbitrary exponents. But it can surprise you with overflow or underflow on intermediate calculations.
Over a sufficiently narrow range of values, most functions are easy enough to approximate. The trick is to find a form that is most economical — you want to perform the minimum number of floating-point additions, multiplications, and divisions on each call to the function. For example, you can approximate essentially any smooth curve over a narrow range with a polynomial that has enough terms. If the curve has an asymptote, however, you may find that you need lots of terms. Such curves favor a rational approximation — a ratio of two polynomials. Computing two smaller polynomials and dividing their values is often faster than computing one larger polynomial.
One thing you do not do is write a loop that tests for any sort of convergence. You can compute the sqrt function, for example, by repeated divide-and-average starting with an initial guess. Know the quality of the guess and you can precompute how many times to iterate. You can compute the sin function, for another example, by truncating its Taylor series expansion. Know the range of arguments you must accept and you can precompute how many terms to keep. You want to avoid messy and time-consuming comparisons.
If a polynomial can do the job, it is usually the approximation of choice. Horner's rule lets you evaluate a polynomial of order N with a simple multiply-add loop:
double y = c[0];
int i = 0;
while (++i <= N)
y = y * x + c[i];
Here, the coefficients are stored in the constant array c.To approximate a function with a polynomial, you can often use linear least-squares. Say you want to approximate the function f(x) with a quadratic (second-order) polynomial over the interval [a, b]. Then you want to minimize the sum S defined as:
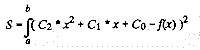
If you remember enough calculus, this approach is much easier than you might at first think. Differentiate S with respect to each of the Ci and set each result to zero. You end up with three linear equations in three unknowns. You have to know how to integrate terms such as f(x)* xn, then solve the set of equations to sufficient precision. Survive all those obstacles and you get a neat approximation.
One way to save some of that work is to find an infinite-series representation of the function you wish to approximate. Then all you have to do is decide where to chop it off for the precision you need. If you want to be extra tidy, you can then economize the result by using Chebychev polynomials. That reduces the number of terms you must compute for the same degree of precision. It also spreads the error out over the entire range instead of bunching it at one end. (For an excellent guide to understanding and using this approach, see R.W. Hamming, Numerical Methods for Scientists and Engineers, McGraw-Hill Book Co. Inc, New York, 1962).
So another recipe for finding a polynomial approximation is:
- Find a series representation that converges.
- Determine where it's safe to truncate the series.
- Economize it to get a smaller polynomial with better error properties.
You can obtain better approximations using more advanced techniques. John F. Hart, et al., Computer Approximations, (Robert E. Krieger Publishing Company, Malabar, Florida, 1978) shows you quite a few. This book is also chock full of carefully computed approximations to the most widely used math functions. You can often find one with just the precision you need.
An excellent book on writing math libraries is William J. Cody, Jr. and William Waite, Software Manual for the Elementary Functions, (Prentice-Hall, Inc., Englewood Cliffs, N.J., Inc., 1980). Many of the functions I wrote for <math.h> make use of algorithms and techniques described by Cody and Waite. Quite a few use the actual approximations derived by Cody and Waite especially for their book. I confess that on a few occasions I thought I could eliminate some of the fussier steps they recommend. All too often I was proven wrong. I happily built on the work of these careful pioneers.
As a final note on resources, the acid test for many of the functions declared in <math.h> was the public-domain ELEFUNT (for "elementary function") tests. These derive from the carefully wrought tests in Cody and Waite. To obtain a copy, mail to the Internet address netlib@research. att.com the request:
send index from elefunt
Programming Techniques
I have said just about all I intend to say about the numerical techniques behind the math functions. Others have done a better job of explaining that topic than I can do. Go read the books mentioned above if you want to learn more. In what follows, my primary interest is what you can do programming in C and for the C programmer.The functions in <math.h> vary widely. I find it best to discuss them in several groups. I begin with a few special constants and a brief sample of the functions that follow. The sample shows some of the seminumerical functions that manipulate the components of floating-point values, such as the integer, fraction, and exponent parts. Along the way, I also present several low-level primitives. These are used by all the functions declared in <math.h> to isolate dependencies on the specific representation of floating-point values.
I discussed earlier the general properties of machines covered by this particular set of primitives. I emphasize once again that the parametrization doesn't cover all floating-point representations used in modern computers. You may have to alter one or more of the primitives for certain computer architectures. In rarer cases, you may have to alter the higher-level functions as well.
I'll start with the definition of the macro HUGE_VAL. I define it as the data object _Hugeval and initialize it with the IEEE 754 code for +Inf. To do so, I introduce the type _Dconst. It is a union that lets you initialize a data object as an array of four unsigned shorts, then access the data object as a double. The data object _Hugeval is one of a handful of floating-point values that are best constructed this way.
Listing 1 shows the file xvalues.c that defines this handful of values. It includes a definition for_Inf that matches _Hugeval. I provide both in case you choose to alter the definition of HUGE_VAL. The file also defines:
- _Nan, the code for a generated NaN that functions return when no operand is also a NaN but the result is a NaN
- _Rteps, the square root of DBL_EPSILON (approximately), used by some functions to choose between different approximations
- _Xbig, the inverse of _Rteps._D, used by some functions to choose between different approximations
The file xvalues.c is essentially unreadable. It makes extensive use of system-dependent parameters defined in the internal header <yvals.h>. I use this internal header throughout the library to summarize the properties of a given system. xvalues.c does not directly include <yvals.h>. Instead, it includes the internal header "xmath.h" that includes <yvals.h> in turn. All the files that implement <math.h> include "xmath.h". Since that file contains an assortment of distractions, I show it in pieces as the need arises.
The macros defined in "xmath.h" that are relevant to xvalues.c are:
#define _DFRAC ((1<<_DOFF)-1) #define _DMASK (0x7fff&~_DFRAC) #define _DMAX ((1<< (15-_DOFF))-1) #define _DNAN (0x8000|_DMAX<<_DOFF|1<<(_DOFF-1))All these values build on the value of the macro _DOFF, defined in <yvals.h>. It specifies the offset in bits of the characteristic in the most-significant word of a double. For IEEE 754, it has the value 4. For the VAX, it has the value 7.
If you can sort through this nonsense, you will observe that:
- The code for Inf has the largest-possible characteristic (_DMAX) with all fraction bits zero.
- The code for generated NaN has the largest-possible characteristic with the most-significant fraction bit set.
The presence of all these codes makes even the simplest functions nontrivial. For example, Listing 2 shows the file fabs.c. In a simpler world, you could reduce it to the last return statement:
return (x < 0.0 ? -x : x);Here, however, we want to handle NaN, -Inf, and +Inf properly along with zero and finite values of the argument x. That takes a lot more testing.
xdtest.c in Listing 3 defines the function _Dtest that categorizes a double value. The internal header "xmath.h" defines the various offsets and category values that _Dtest uses. The macro definitions of interest here are:
/* word offsets within double */
#if_DO==3
#define _D1 2 /* little-endian order */
#define _D2 1
#define _D3 0
#else
#define _D1 1 /* big-endian order */
#define _D2 2
#define _D3 3
#endif
/* return values for _D functions */
#define FINITE -1
#define INF 1
#define NAN 2
The header <yvals.h> defines the macro _DO as either the value 3 or zero. It is the index of the most-significant word in a double. Hence, it specifies the order in which words appear in memory (sometimes known as "byte sex").Note that a floating-point value with characteristic zero is not necessarily zero. IEEE 754 supports gradual underflow. The value is zero only if all bits (other than the sign) are zero.
In Times To Come
This sampler should give you a feel for the basic approach. Next month, I start through the math library in earnest. Remember that my goal is not to turn all C programmers into numerical analysts. Rather, it is to give you a better idea of what goes on when you call a library function. That should teach you where to be alert for problems. It should also teach you to use, and to appreciate, a good math library when you find one.