P.J. Plauger is senior editor of The C Users Journal. He is secretary of the ANSI C standards committee, X3J11, and convenor of the ISO C standards committee, WG14. His latest book is Standard C, which he co-authored with Jim Brodie. You can reach him at pjp@plauger.uunet.
Introduction
Floating point arithmetic is complicated stuff. Many small processors don't even support floating point arithmetic with hardware instructions. Others require a separate coprocessor to handle such arithmetic. Only the most complex computers include floating point support in the standard instruction set.There's a pragmatic reason why chip designers often omit floating point. It takes about the same amount of microcode to implement floating add, subtract, multiply, and divide as it does all the rest of the instructions combined. You can essentially halve the complexity of a microprocessor by leaving out floating point support.
Many applications don't need floating point arithmetic at all. Others can tolerate reasonably poor performance, and a few kilobytes at extra code, by doing the arithmetic in software. The few that need high-performance arithmetic often make other expensive demands on the hardware, so the extra cost of a coprocessor is an acceptable perturbation.
C spent its early years on a PDP-11/45 computer. That strongly colored the treatment of floating point arithmetic in C. For instance, the types float (for 32-bit format) and double (for 64-bit format) have been in the language from the earliest days. (Those were the two formats the PDP-11 supported.) That is a bit unusual for a system-implementation language, and a "small" one at that. Who knows what would have happened had that machine not been equipped with the optional Floating Point Processor (FPP)?
The PDP-11/45 FPP could be placed in one of two modes. It did all arithmetic either with 32-bit operands or with 64-bit operands. You had to execute a oneword instruction to switch modes. On the other hand, you could load and convert an operand of the wrong size just as easily as you could load one of the expected size. That strongly encouraged leaving the FPP in one mode. It is no surprise that C for many years promised to produce a double result for any operator involving floating point operands, even one with two float operands. Not even FORTRAN was so generous.
As C migrated to other machines, this heritage sometimes became a nuisance. Those of us who felt obliged to supply the full language had to write floating point software for some pretty tiny machines. I put up PDP-11 style floating point on the Intel 8080 (plus Intel 8085 and Zilog Z80). I can assure you that it wasn't easy.
Machines that supported floating point as standard hardware present a different set of problems. Chances are, the formats are slightly different. That makes writing portable code much more challenging. You need to write math functions and conversion algorithms to retain varying ranges of values and varying amounts of precision. I learned more than I ever wanted to know about portability while debugging this code.
Machines that provide floating point as an option combine the worst of both worlds, at least to us compiler implementors. We had to provide software support for those machines that lacked the option. We had to make use of the machine instructions when the option was present. And we had to deal with confused customers who linked two flavors of code, or the wrong version of the library.
Standards Issues
From a linguistic standpoint, however, most of these issues are irrelevant. The main problem the drafters of the C Standard had to deal with was excess variety. It is a longstanding tradition in C to take what the machine gives you. A right shift operator does whatever the underlying hardware does most rapidly. So, too, does a floating add operator. Neither result may please a mathematician.With floating point arithmetic, you have the obvious issues of overflow and underflow. A result may be too large to represent on one machine, but not on another. The resulting overflow may cause a trap, may generate a special code value, or may produce garbage that is easily mistaken for a valid result. A result may be too small to represent on one machine, but not on another. The resulting underflow may cause a trap or may be quietly replaced with an exact zero. Such a "zero fixup" is often a good idea, but not always.
Novices tend to write code that is susceptible to overflow and underflow. The broad range of values supported by floating point lures the innocent into a careless disregard. Your first lesson is to estimate magnitudes and avoid silly swings in value.
You also have the more subtle issue of significance loss. Floating point arithmetic lets you represent a tremendously broad range of values, but at a cost. A value can be represented to only a fixed precision. Multiply two values that are exact and you can keep only half the significance you might like. Subtract two values that are very close together and you can lose most or all of the significance you were carrying around.
Workaday programmers most often run afoul of unexpected significance loss. That formula that looks so elegant in a textbook is an ill-behaved pig when reduced to code. It is hard to see the danger in those alternating signs in adjacent terms of a series. Until you get burned, that is, and learn to do the subtractions on paper instead of at runtime.
Overflow, underflow, and significance loss are intrinsic to floating point arithmetic. They are hard enough to deal with on a given machine. Writing code that can move across machines is harder. Writing a standard that tells you how to write portable code is harder still. But another problem makes the matter even worse.
Two machines can use the same representation for floating point values. Yet you can add the same two values on each machine and get different answers! The result can depend, reasonably enough, on the way the two machines round results that cannot be represented exactly. You can make a case for truncating toward zero, rounding to the nearest representable value, or doing a few other similar but subtly different operations.
Or you can just plain get the wrong answer. In some circles, getting a quick answer is considered much more virtuous than getting one that is as accurate as it could be. Seymour Cray has built several successful computer companies catering to this constituency. These machines saw off precision somewhere in the neighborhood of the least significant bit that is retained. Sometimes that curdles a bit or two having even more significance. There are even some computers (not designed by Cray) that scrub the four least significant bits when you multiply by one!
If the C Standard had tried to outlaw this behavior, it would never have been approved. Too many machines still use quick and dirty floating point arithmetic. Too many people still use these machines. To deny them the cachet of supporting conforming C compilers would be commercially unacceptable.
As a result, the Standard is mostly descriptive in the area of floating point arithmetic. It endeavors to define enough terms to talk about the parameters of floating point. But it says little that is prescriptive about getting the right answer.
Committee X3J11 added the standard header <float.h> as a companion to <limits.h>. The latter is historically misnamed. It should more properly be called <integer.h>, since it deals with the properties of integer data representations and arithmetic. Rather than muck up an existing header (that we share with the POSIX Standard), we added yet another.
We put into <float.h> essentially every parameter that we thought might be of use to a serious numerical programmer. From these macros, you can learn enough about the properties of the target machine, presumably, to code your numerical algorithms wisely. (Notwithstanding my earlier slurs, the major push to help this class of programmers came from Cray Research.)
What The Standard Says
The Library section of the Standard has little to say about <float.h>:
4.1.4 Limits <float.h> and <limits.h>
The headers <float.h> and <limits.h> define several macros that expand to various limits and parameters.The macros, their meanings, and the constraints (or restrictions) on their values are listed in 2.2.4.2. [end of quote]
You have to backtrack to the Environment section to get the real meat:
2.2.4.2.2 Characteristics of Floating Types <float.h>
The characteristics of floating types are defined in terms of a model that describes a representation of floating-point numbers and values that provide information about an implementation's floating-point arithmetic.10 The following parameters are used to define the model for each floating-point type:s sign (1)
b base or radix of exponent representation (an integer > 1)
e exponent (an integer between a minimum emin and a maximum emax)
p precision (the number of base-b digits in the significand)
fk nonnegative integers less than b (the significand digits)
A normalized floating-point number x (1 > 0 if x 0) is defined by the following model:
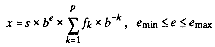
Of the values in the <float.h> header, FLT_RADIX shall be a constant expression suitable for use in #if preprocessing directives; all other values need not be constant expressions. All except FLT_RADIX and FLT_ROUNDS have separate names for all three floating-point types. The floating-point model representation is provided for all values except FLT_ROUNDS.
The rounding mode for floating-point addition is characterized by the value of FLT_ROUNDS :
-1 indeterminable
0 toward zero
1 to nearest
2 toward positive infinity
3 toward negative infinity
All other values for FLT_ROUNDS characterize implemention-defined rounding behavior.
The values given in the following list shall be replaced by implementation-defined expressions that shall be equal or greater in magnitude (absolute value) to those shown, with the same sign:
- radix of exponent representation, b
FLT_RADIX 2
FLT_MANT_DIG DBL_MANT_DIG LDBL_MANT_DIG
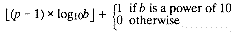
FLT_DIG 6 DBL_DIG 10 LDBL_DIG 10
FLT_MIN_EXP DBL_MIN_EXP LDBL_MIN_EXP
FLT_MIN_10_EXP -37 DBL_MIN_10_EXP -37 LDBL_MIN_10_EXP -37
FLT_MAX_EXP DBL_MAX_EXP LDBL_MAX_EXP
FLT_MAX_10_EXP +37 DBL_MAX_10_EXP +37 LDBL_MAX_10_EXP +37The values given in the following list shall be replaced by implementation-defined expressions with values that shall be equal to or greater than those shown:
- maximum representable finite floating-point number, (1 - b-p) bemax
FLT_MAX 1E+37 DBL_MAX 1E+37 LDBL_MAX 1E+37The values given in the following list shall be replaced by implementation-defined expressions with values that shall be equal to or less than those shown:
- the difference between 1.0 and the least value greater than 1.0 that is representable in the given floating point type, b1-p
FLT_EPSILON 1E-5 DBL_EPSILON 1E-9 LDBL_EPSILON 1E-9
FLT_MIN 1E-37 DBL_MIN 1E-37 LDBL_MIN 1E-37Footnote:
10. The floating-point model is intended to clarify the description of each floating-point characteristic and does not require the floating-point arithmetic of the implementation to be identical. [end of quote]
Implementing <float.h>
In principle, this header consists of nothing but a bunch of macro definitions. For a given implementation, you merely determine the values of all the parameters and plug them in. A common implementation these days is based on a fairly recent standard for floating point arithmetic called IEEE-754. Older machines, such as System/370 and VAX, still have floating point formats that are proprietary. Newer chips, however, tend to follow this standard. You will find IEEE-754 floating point arithmetic in the coprocessors for the Intel 80X86 family and the Motorola 680X0 family, to name just two very popular lines. It is a very complex standard (some say too complex), but only its grosser properties affect <float.h>.The following header assumes that long double has the same representation as double. The former can have an 80-bit representation in the IEEE standard, but it doesn't have to. For this common case, you can copy the values out of an example in the Standard:
/* float.h standard header -
IEEE-754, 4/8/8
*/
#ifndef _FLOAT
#define _FLOAT
/* double properties */
#define DBL_DIG 15
#define DBL_EPSILON
2.2204460492503131E-16
#define DBL_MANT_DIG 53
#define DBL_MAX
1.7976931348623157E+308
#define DBL_MAX_10_EXP 308
#define DBL_MAX_EXP 1024
#define DBL_MIN 2.2250738585072014E-308
#define DBL_MIN_10_EXP -307
#define DBL_MIN_EXP -1021
/* float properties */
#define FLT_DIG 6
#define FLT_EPSILON 1.19209290E-07F
#define FLT_MANT_DIG 24
#define FLT_MAX 3.40282347E+38F
#define FLT_MAX_10_EXP +38
#define FLT_MAX_EXP +128
#define FLT_MIN 1.17549435E-38F
#define FLT_MIN_10_EXP -37
#define FLT_MIN_EXP -125
/* common properties */
#define FLT_RADIX 2
#define FLT_ROUNDS -1
/* long double properties */
#define LDBL_DIG 15
#define LDBL_EPSILON 2.2204460492503131E-16L
#define LDBL_MANT_DIG 53
#define LDBL_MAX 1.7976931348623157E+308L
#define LDBL_MAX_10_EXP 308
#define LDBL_MAX_EXP 1024
#define LDBL_MIN 2.2250738585072014E-308L
#define LDBL_MIN_10_EXP -307
#define LDBL_MIN_EXP -1021
#endif
You may find a few problems, however. Not all translators are equally good at converting floating point literals. Some may curdle the least significant bit or two. That could cause overflow or underflow in the case of some extreme values such as DBL_MAX and DBL_MIN. Or it could ruin the critical behavior of other values such as DBL EPSILON.At the very least, you should check the bit patterns produced by these values. You can do that by stuffing the value into a union one way, then extracting it another way, as in:
union {
double dval;
unsigned short w[4];
} dmax = DBL_MAX;
Here, I assume that unsigned short occupies 16 bits and double is the IEEE-754 64-bit representation. Some computers store the most significant word at dmax.w[0], others at dmax.w[3]. You have to check what your implementation does. Whatever the case, the most significant word should have the value 0x7FEF, and all the others should equal 0xFFFF.A safer approach is to do it the other way around. Initialize the union as a sequence of bit patterns, then define the macros to access the union through its floating point member. Since you can only initialize the first member of a union, you must reverse the member declarations from the example above. You must also give them funny names, to avoid collisions with any user-defined macros.
With this approach, you would place the following definitions and declarations in <float.h>:
typedef union {
unsigned short _W[4];
double _D;
} _Dtype;
.....
extern_Dtype _Dmax, _Dmin,
_Deps;
#define DBL_MAX _Dmax._D;
#define DBL_MIN _Dmin._D;
#define DBL_EPSILON _Deps._D;
Then in a library source file, you provide a definition for _Dmax. For the 80X86 family, which has the least-significant word first, you write:
#include <float.h>
.....
_Dtype _Dmax = {{0xFFFF, 0xFFFF,
0xFFFF, 0x7FEF}};
_Dtype _Dmin = {{0x0000, 0x0000,
0x0000, 0x0010}};
_Dtype _Deps = {{0x0000, 0x0000,
0x0000, 0x3CB0}};
(Warning: I haven't tested all these values, yet. Beware of errors, particularly of the off-by-one variety.)The macros you define this way have one small drawback. You cannot use them to initialize static data. (That includes components of aggregates such as structures and arrays, whether static or dynamic.) In other words, you cannot write:
#include <float.h> ..... static BigD = DBL_MAX;/* WRONG! */The macro expands to an rvalue expression, not a constant expression as required for a static initializer. Such a definition is permitted by the Standard. Only FLT_RADIX need be an expression usable in a #if directive. (An implementation may not change the number base it uses for floating point arithmetic after translation time. This was not viewed as a serious restriction.)
Note, by the way, that FLT_ROUNDS can also be an rvalue expression. The rounding mode can change during execution. How you change it is not specified in the Standard, but you can test whether it has changed. Just inspect the current value of FLT_ROUNDS. Modern coprocessors such as the Intel 80X87 family and the Motorola 68881 indeed permit limited program control over the rounding mode. The C Standard merely acknowledges reality.
Conclusion
Having said all this, I feel obliged to tell you to forget most of it. Only the most sophisticated of numerical programs care about most of these parameters. Only the most sophisticated of programmers know how to write code that adapts well to changes among floating representations.In all my years of scientific programming, I have found good use for only the *_MAX parameters. I use these to build tables for converting between floating point and integer. When I want the code to be highly portable, I conditionally include the last few entries based on the range of numbers. That is the sort of thing that you worry about behind the scenes. It is not likely to appear in a typical application.
You should have some awareness of the peculiarities and pitfalls of floating point arithmetic. You should know the safe ranges and precisions for floating point values in portable C code and in code you write for your workaday machines. You can use some of the parameters in <float.h> to build safety checks into your code.
But don't think that this header contains some key ingredient for writing highly portable code. It doesn't.