Louis Baker has a Ph.D. in astronomy and has written books with code in C and Ada for McGraw-Hill. He may be reached at Mission Research Corp., 1720 Randolph SE, Albuquerque NM 87106.
In the May issue, I presented header files designed to simplify the programming of complex arithmetic and matrices in C. In this article, I will demonstrate that using C++ could further simplify such programming.
Developing these programs was my first foray into C++. By mentioning some of my misconceptions and stumbling blocks, I hope to ease the way of other C programmers taking up C++. After developing these programs with Zortech C++, I got my hands on Turbo C++. I will compare the two and comment on porting between C++ compilers.
Complex Arithmetic
In my previous article (May 1990), I gave an example of a program to compute a type of Bessel functions, called Kelvin functions, using complex arithmetic. (If you aren't familiar with complex numbers, see the previous article.) Here, you will use a header file, COMPLEX.HPP (Listing 1) , to facilitate complex arithmetic, which employs operator overloading. This header enables you to add two complex numbers, a and b, to produce c, with code of the form c=a+b rather than CADD(c,a,b) as was required with COMPLEX.H. The code is straightforward and needs no discussion. The simplest routines are inline for efficiency.I will illustrate using the code by calculating the Hurwitz Zeta function z(s,a), which is used in various applications, including summing series and number theory. It is defined as
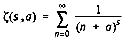
The Riemann zeta function is z(s,1). Spanier and Oldham give an efficient formula for evaluating this function, which contains two summations and one additional term. The first summation is finite, with specified upper limit, and the second is infinite, with the terms depending on the upper limit specified for the first sum. They then set the first sum equal to zero, and use a rational approximation method to obtain the second sum. There is an associated cost: for n terms, order n2 operations are required vs. order n for summing the series. The added operations include division. The rational approximation generally converges more rapidly than summing the series, except for large |s|. I have made two changes to their method. First, I have re-introduced the first summation, which improves behavior for large |s|. Second, while they computed the second sum for a fixed number of terms, I check the convergence of that sum and terminate when a given tolerance is achieved. I limit the sum to a maximum of 80 terms to prevent problems with overflow. The program, along with support routines for computing and printing the logarithm and exponential of a complex number, as its absolute value (magnitude) is given in Listing 2. Note the need to delete the storage allocated to the h array.
Vectors And Matrices
Vectors and matrices of complex numbers can take advantage of C++ features, notably operator overloading, to ease the programmer's burden. While a vector can be implemented as a matrix with a single row or column, it is more efficient to treat it as a distinct class. Listing 3, CVECTOR.HPP, defines the vector class and Listing 4, CMATRIX.HPP, the matrix class, with the functions and test program main() in Listing 5, CMATRIX.CPP. You can find a number of matrix class implementations in Using C++ by Bruce Eckel, and in J. F. Dreitlein and J. R. Sauer's article, "Spinor Software Tools in C++" in Computers in Physics magazine (see Reference at the end of this article). I was initially tempted to implement the matrix as a vector of row vectors of class Cvector, but I decided to follow the usual practice (as in the two cited references) of using a single variable of type complex **head. With this practice, the natural notation head[i][j] represents the appropriate matrix element.The classes Cvector and Cmatrix carry along an integer variable named base. The default value, 0, gives the usual C convention of vectors with a first element of index 0. Set base=1 for the FORTRAN convention of first element having the index 1. The latter choice might be useful in converting FORTRAN code or a mathematical formula with the usual notation of row and column indices beginning at 1.
Eckel implements matrices by doing his own memory management. Each matrix has a reference count, and the destructor deletes the storage required only if this count is one. He also copies matrices by assigning the pointer and increasing the reference count. This method is economical in time, and probably storage, but it is dangerous. Altering one reference to the matrix will alter all other copies. The reference count method of storage allocation can sometimes fail to free storage when it is possible to do so, for example if there is a circular chain of references.
A safer method is to define the copy operators Cmatrix(Cmatrix&) and Cvector(Cvector&) to allocate new memory and copy all the data. This costs time and perhaps space, but avoids the two problems mentioned for the other scheme. Obviously, there are time-critical applications in which the pointer-copying approach could be desirable. Depending on the application, the extra memory occupied by multiple copies may or may not outweigh the space occupied by the reference count in each object, and any unrecovered memory due to circular chains.
The package CMATRIX.HPP implements the most basic operations, including taking the dot product of two vectors, and multiplying two matrices or a vector by a matrix. Eckel's package contains a large number of routines, includes factoring matrices into their LU decomposition, performing statistical operations, and interchanging rows or columns. Interested readers might start by converting the Basic Linear Algebra Subroutines (BLAS) package to C++, and using its functions to implement more complicated matrix operations.
Inheritance
I had originally intended to use inheritance, but discovered it wasn't very useful for the problems at hand. For example, I couldn't use complex as a base class from which complex vectors were derived. I could have defined vectors based at 0 as the base class, and define a class with arbitary bases that inherits from that base class and adds the integer variable base. This might save some storage and arithmetic if the user wants to use indices based at 0, but it seems more sensible to "do it right" from the start.I found the data hiding features of C++ unhelpful at best. For example, I had originally placed the function error() as a function in Cvector. It was then inaccessable to functions in the Cmatrix class, unless I declared that class a friend. I would have to modify CVECTOR.HPP whenever I decided there was another use for the function as constituted.
C++ is best suited to bottom-up programming. Bottom-up programming entails building tools, such as reusable routines that are often based on less sophisticated existing code. Inheritance is ideal for this. On the other hand, there seems to me to be little value to inheritance for the first shot at code, since you can build in the structure you need. Inheritance is useful only when you want to reuse a class that isn't quite up to snuff.
Comments On Zortech And Turbo C++
The Zortech compiler comes with two programs to do the second pass. If the first version runs out of memory doing the compilation, you try the second. If that one runs out of memory, you are out of luck. It's also possible to run out of memory on the first pass. These features enforce code modularity, because the first version did not tolerate even moderately sized programs.Zortech and other C++ compilers use name "mangling,". This means that the compiler sees a function like this:
FILE *OpenFile(const char *FileName,
const char *IoMode=0);
the symbol name that it actually places in the object code might be something like OpenFile___NpCcT1. The funny characters at the end are an encoding of the fact that this function takes two arguments which are both near pointers to constant characters.The purpose of this is encoding is to allow the linker to detect some kinds of type errors. For example, if I referenced the function shown in the previous paragraph, but defined it incorrectly as
FILE *OpenFile(const char *FileName);then, because functions that accept different types of arguments are given different names, the linker would object that the function that was referenced had not been defined. Unfortunately, the Zortech linker displays the mangled names in its error messages (there is an extra utility that unmangles them as an extra step). The Turbo linker automatically unmangles the names in its error messages, so you don't have to think about it.
Turbo C++ has a much snazzier appearence than the previous release of Turbo C. This comes at some cost. Before, the F3 function key instantly gave you a window for a file to load. Now, you have to wait a few seconds, depending upon the speed of your host machine and the clutter of your disk, while it develops a directory of your files. You'll have to throw away your old project files (*.PRJ) as the format has changed. In fact, so much has changed you'll find yourself re-learning how to use the program. (For example, if you are mouseless and want to search backwards, you now need to use the tab key to get to the option for backward searches, as the return will now begin the search.) But don't throw away your old C code or object modules. These may still be linked to, either with Zortech's cdecl keyword declaration or with Turbo C's extern "C" declaration.
Both programs generated .EXE files of similar size and speed. Be prepared for the additional language complexity to slow compilations compared to straight C compilers. That does not imply a runtime overhead, however. In fact, Zortech can generate more efficient function call/return code for C++ functions because the required function prototype guarantees the number and type of function parameters.
Turbo C++ was pickier than the Zortech, catching a missing void declaration for a function which returned nothing. There were also minor differences in the languages accepted by the two compilers. Turbo C++ attempts to implement the language strictily as defined by AT&T's release 2.0, whereas Zortech has some features of AT&T release 2.1.
For example, the 2.0 definition of C++ did not allow you to define an array of class objects unless that class contained a constructor that took no arguments. That made sense because the constructor would be getting called implicitly in a loop by the compiler to initialize each object in the array — there is no way for you to specify arguments to the constructor in that situation.
However, the 2.1 definition of C++ loosened that restriction a little by also allowing constructors that have only arguments with default values specified. That allows a little more flexibility for the programmer with only a small increase in complexity for the compiler. The net result was a constructor
complex ( double reali=0.,
double imagi=0.)
that allowed statements like
complex *head; head = new complex[10];with Zortech, but Turbo complained that complex::complex() was not defined. Because of the speed at which C++ is evolving, minor incompatibilities like this are a fact of life for C+ + programmers.
References
J. F. Dreitlein & J. R. Sauer, "Spinor Software Tools in C++", Computers in Physics, Jan./Feb. 1990, p.64.Bruce Eckel, Using C++, N.Y.: Osborne/McGraw-Hill,1989.
C. L. Lawson, R. J. Hanson, D. R. Kincaid, F. T. Krough, "Algorithm 539: Basic Linear Algebra Subprograms for Fortran Use", Collected Algorithms from ACM (CALGO), also "ACM Transactions on Mathematical Software", 5,p.324,1979.
J. Spanier and K. B. Oldham, Handbook of Functions, N.Y.: Hemisphere, 1987.
Vendors
Zortech C++Zortech Inc.
1165 Massachusettes Ave.
Arlington, MA 02174
(617) 646-6703
FAX (617) 643-7969
(800) 848-8408
UK (44) 81-316-7777
Turbo C++ v2.0
Borland Int'l
P.O. Box 660001
Scotts Valley, CA 95067-0001
(800) 331-0877
outside USA 408-438-5300